cbaWorkfow application
cbaWorkflow application is a Linux based workflow application which creates a set of execution nodes for Big Data and warehouse projects. It is written in C++ and uses free Linux libraries
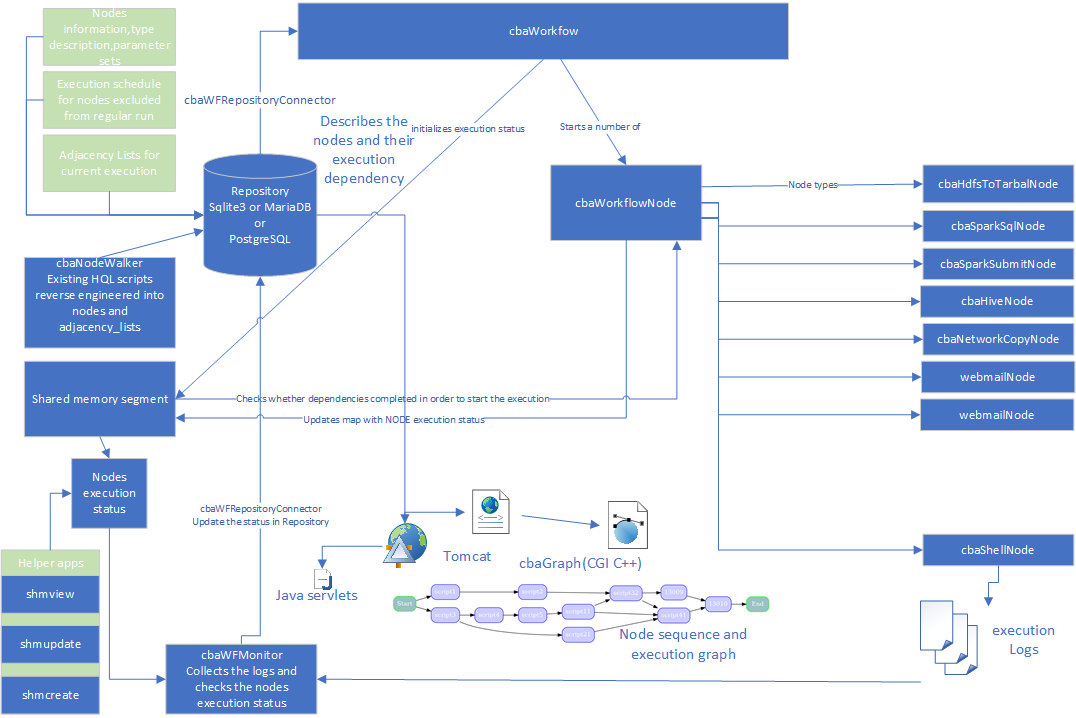
cbaWorkflow keeps track of the execution schedule, states of the nodes, involves data consistency verification in a set of nonblocked components coordinated by the main execution engine. The execution status is kept in shared memory, so service applications can have access to the map to modify it, if required or obtain a real time information. Other applications can check the execution status from the database repository table. CbaWorkflow persists the map to database on a set interval.General description
- Workflow will obtain the description of the nodes from a repository (postgreSQL database) and will instantiate node objects.
- Workflow will start a set of nodes which will execute themselves
- the nodes are starting in levels of dependency, so that resources are not wasted on the nodes which do not yet hav to execute
- workflow will obtain the dependencies of the current run from repository and pass the dependency to every node it creates.
- each node knows what it depends on by storing an vector of node ids they depend on(reverse adjacency list)
- the nodes will know how to execute themselves
- the nodes will have a method which will run the execution when the dependencies have completed, or sleep if the dependency have not resolved and keep polling the execution status in shared memory segment
- the nodes will update a map in shared memory with their progress
- the nodes will check a shared memory map whether the nodes they depend on have completed execution
- workflow will keep the list of the allocated node objects and delete them after their job is completed
- workflow will rerun the node which failed execution
- workflow will monitor the progress of the execution and asynchronously update the database with the information on start time, end time and progress
Overall process
Resources
- repository database,hosted in PostgreSQL or MariaDB or Sqlite3
- repository stores information about the nodes
- repository stores information about the current execution status in a table node_execution_status (node_id, execution_status)
- repository stores information about the current execution status(node_id,start_time,complete_time)
- repository stores information about node dependencies (node_id, parent_node_id)
- Framework is implemented using C++
key elements used:
- cbaWFRepositoryConnector - populates application structures from repository(PostrgreSQL or OS files)
- C libpq library - to retrieve data from postgress, needs to exist on the system where application runs. a cbaWFRepositoryConnector derived class is linked to libpq
- boost_managed_memory, boost_interprocess - to keep the execution status in the shared memory and named semaphores to synchronize the access to shared memory
- cbaGraph - calling the graphviz libraries to generate a graph of execution. The data for the nodes are retrieved from the nodes table in postgres, the dependencies are retrieved from the adjacency_lists table in PostrgreSQL
- cbaNodeWalker - reverse engineering a set of hql/sql scripts to obtain information on the nodes(a script) and execution dependency. It can store the information if files or in nodes, ajacency)lists tables in PostgreSQL as nodeFrom→nodeTo format).
- scala generated jars for spark-submit nodes
- java generated jars for hdfs access
- spark sql scripts for spark-sql nodes
- shell scripts for shell nodes
- Tomcat servlets for generating reports of current status of execution
- Tomcat application to create a set of nodes and populate the dependencies
- Neo4j use is investigated to generate a dependency graph, which could be exported as Cypher query to get a complex list of dependencies.
installation and configuration instructions
Installation of RPM
- login as root
- if the repository for yum is set up then follow the instructions in packaging cbaWorkflow and execute: yum install cbaWorkflow
- If the yum hosted Nexus repository has not been set up ,then obtain the rpm , currently cbaWorkflow-1.0.5-1.x86_64.rpm from Nexus or ftp it :
wget http://192.168.2.22:8081/repository/cbayum-hosted/cbaWorkflow/1.0.5/1/cbaWorkflow-1.0.5-1.x86_64.rpm
In the directory where the rpm is located issue the following command: yum install local cbaWorkflow-1.0.0-1.x86_64.rpm
Installing: cbaWorkflow x86_64 1.0.0-1 /cbaWorkflow-1.0.0-1.x86_64 8.9 M
- Verify the installation:
ls -l /app/cbaWorkflow
rpm -qi cbaWorkflow
Name : cbaWorkflow
Version : 1.0.0
Release : 1
Architecture: x86_64
Install Date: Sat 27 Mar 2021 09:38:29 PM EDT
Group : Applications/File
Size : 9320360
License : available for purchase, free license up to 5 nodes
Signature : (none)
Source RPM : cbaWorkflow-1.0.0-1.src.rpm
Build Date : Sat 27 Mar 2021 04:29:19 PM EDT
Build Host : r02edge.custom-built-apps.com
Relocations : (not relocatable)
Packager : Boris Alexandrov, Custom Built Apps ltd
Vendor : Custom Built Apps ltd, Toronto, Ontario
URL : www.custom-built-apps.com
Summary : workflow application for data pipelines
Description :
The application runs a data pipeline of execution nodes like spark-sql, spark-submit, shell, hdfs commands in orchestration and cadence.
Contains a tomcat based interface for adding the nodes and monitoring the process
check the files list: rpm -ql cbaWorkflow
/app/cbaWorkflow/bin/cbaWFMonitorTest
/app/cbaWorkflow/bin/cbaWorkflowTest
/app/cbaWorkflow/bin/repobuilder
/app/cbaWorkflow/bin/shmcreate
/app/cbaWorkflow/bin/shmupdate
/app/cbaWorkflow/bin/shmview
/app/cbaWorkflow/etc/cbaWorkflow.ini
/app/cbaWorkflow/etc/config6
/app/cbaWorkflow/etc/env.sh
/app/cbaWorkflow/etc/run.sh
/app/cbaWorkflow/lib/libcbaEndNode.so
/app/cbaWorkflow/lib/libcbaGraph.so
/app/cbaWorkflow/lib/libcbaHdfsExecNode.so
/app/cbaWorkflow/lib/libcbaNodeWalker.so
/app/cbaWorkflow/lib/libcbaShellNode.so
/app/cbaWorkflow/lib/libcbaSparkSQLNode.so
/app/cbaWorkflow/lib/libcbaSparkSubmitNode.so
/app/cbaWorkflow/lib/libcbaStartNode.so
/app/cbaWorkflow/lib/libcbaUtils.so
/app/cbaWorkflow/lib/libcbaWFRepositoryConnector.so
/app/cbaWorkflow/lib/libcbaWFRepositoryConnectorPG.so
/app/cbaWorkflow/lib/libcbaWFSharedMemory.so
/app/cbaWorkflow/lib/libcbaWorkflowNode.so
/app/cbaWorkflow/wars/cbaWorkflow.war
Configuring the cbaWorkflow.ini file
the file is located in the /app/cbaWorkflow/etc
-- FILE CONTENTS
dbname=cbaworkflowdb
user=dataexplorer1
password=2MuchTime
hostaddr=192.168.2.30
port=5432
polling_time=15
nodes_log_dir=/home/dataexplorer1/logs
connector_lib=libcbaWFRepositoryConnectorPG.so
--- END OF FILE
repository connector libcbaWFRepositoryConnectorPG.so is used to connect to PostgreSQL server
set database to the database where a repository is going to be created
update the parameters as needed
login as the user who is going to run the pipeline
copy the cbaWorkflow.ini into your home directory as a hidden file
cp /app/cbaWorkflow/etc/cbaWorkflow.ini ${HOME}/.cbaWorkflow.ini
create the directory for logs:
mkdir /home/dataexplorer1/logs
Setting the environment
login as the user which is going to be running datapipeline.
copy the /app/cbaWorkflow/etc/env.sh to your directory
cp /app/cbaWorkflow/etc/env.sh $HOME
chmod 755 env.sh
vi env.sh
verify the variables match your environment.
add the path to libstdc++.so.6x to LD_LIBRARY_PATH as the first entry, e.g if /usr/local/lib64/libstdc++.so
then edit the LD_LIBRARY_PATH as follows:
export LD_LIBRARY_PATH=/usr/local/lib64:${CBAWF_HOME}/lib:${LD_LIBRARY_PATH}
source the env.sh:
. env.sh
verify the environment:
[dataexplorer1@r01edge ~]$ env | grep CBA
CBAWFINI=/home/dataexplorer1/.cbaWorkflow.ini
CBAWF_HOME=/app/cbaWorkflow
env | grep PATH
LD_LIBRARY_PATH=/usr/local/lib64:/app/cbaWorkflow/lib:/app/cbaWorkflow/lib:/app/hadoop/lib/native:
PATH=/app/cbaWorkflow/bin:/app/cbaWorkflow/bin:/app/spark/bin:/app/spark/sbin:/app/oozie/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/app/hadoop/sbin:/app/hadoop/bin}:/app/hadoop/sbin:/app/hadoop/bin:/home/hdfs/hadoop/sbin:/home/hdfs/hadoop/bin:/app/hive/bin:/app/spark/bin:/home/dataexplorer1/.local/bin:/home/dataexplorer1/bin
which repobuilder
/app/cbaWorkflow/bin/repobuilder
verify there are no unresolved symbols in repobuilder
[dataexplorer1@r01edge ~]$ ldd -r $(which repobuilder)
linux-vdso.so.1 => (0x00007ffca33a8000)
librt.so.1 => /lib64/librt.so.1 (0x00007fc2a7f92000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x00007fc2a7d76000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007fc2a7b72000)
libcbaWFRepositoryConnector.so => /app/cbaWorkflow/lib/libcbaWFRepositoryConnector.so (0x00007fc2a796f000)
libcbaUtils.so => /app/cbaWorkflow/lib/libcbaUtils.so (0x00007fc2a772b000)
libstdc++.so.6 => /usr/local/lib64/libstdc++.so.6 (0x00007fc2a73b0000)
libm.so.6 => /lib64/libm.so.6 (0x00007fc2a70ae000)
libgcc_s.so.1 => /usr/local/lib64/libgcc_s.so.1 (0x00007fc2a6e97000)
libc.so.6 => /lib64/libc.so.6 (0x00007fc2a6ac9000)
/lib64/ld-linux-x86-64.so.2 (0x00007fc2a819a000)
Creating the repository
verify the values in cbaWorkflow.ini are correct for the database, which is going to be a repository.
the user in the connection parameters needs to be able to create tables in the database
cat $CBAWFINI
edit if needed
run the generate repository program repobuilder
repobuilder
Generating a new cbaWorkflow repository
Verify the tables have been created in the repository database,using PostgreSQL interface: