Databricks info
Provided by Microsoft with Azure subscription, it uses spark for its workings and Azure storage. Azure storage comes in dbfs and blob storage varieties, with GenLake 2 system being the derived modern component encompassing the both storage systems
Testing and proof of concept work is done using notebooks, sporting scala, python and sql language options. The scala jars or python wheels and eggs can be uploaded and executed in the Databricks using REST API calls by curl, or some interfaces which encapsulate REST API calls. For the application to run a cluster needs to be created and started. This can be done in advance or as part of the REST API call.General description
- Web interface is available for those who got the subscription
- Clusters can be created and started from the web interface
- Data can be uploaded to dbfs and blob storage using web interface and Data Storage explorer application
- Data can be analyzed using notebooks.
- Libraries can be uploaded and attached to the clusters to be used in the notebooks
- Applications packaged as scala jars or python wheels/eggs can be uploaded using upload functionality
working with notebooks
- Sign in with Azure ID
- To create a new notebook, select New from the navigation menu, and then select notebook
Uploading a jar
After creating a jar on prem and its testing it can be uploaded to DatabricksThere are several ways to upload the jar.
if the upload button is avaialable in data/dbfs, then the dbfs location can be selected and the file could be uploaded there
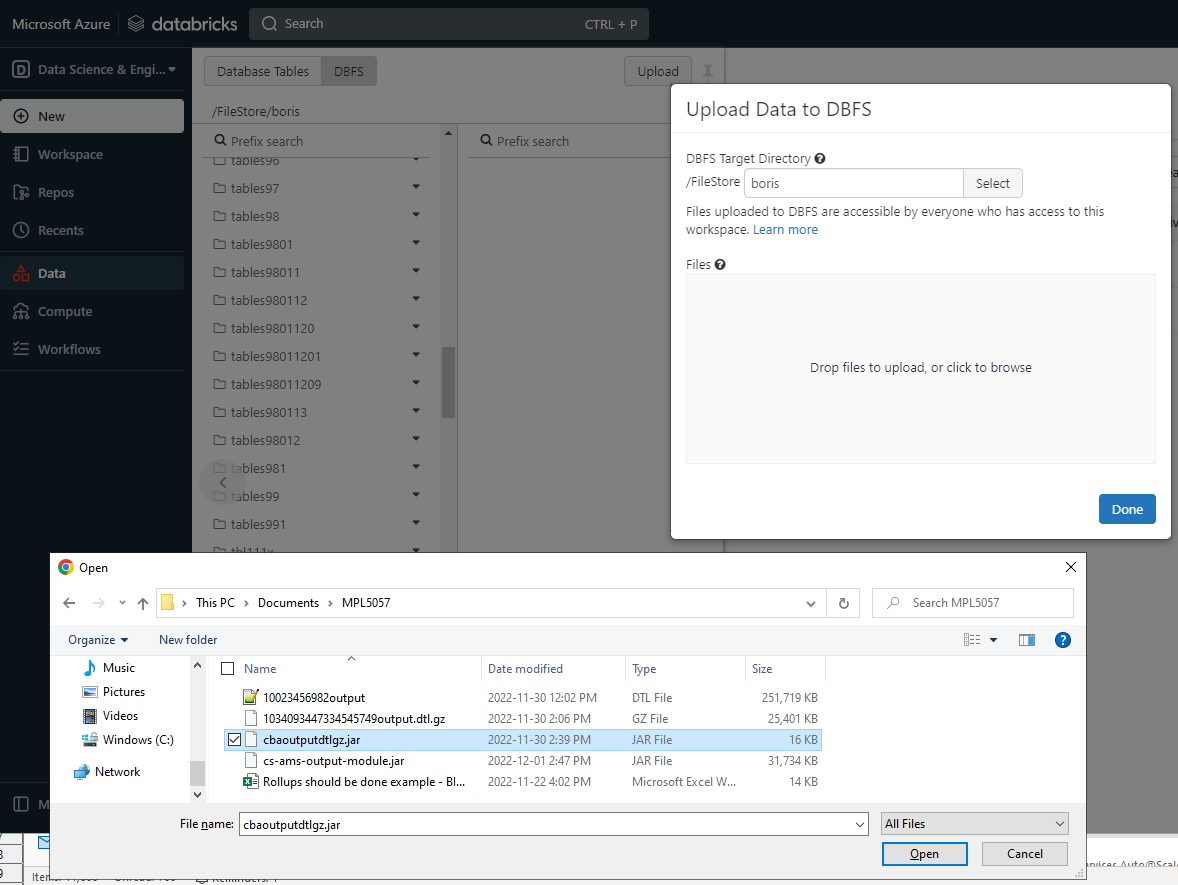
if the upload button is not available, then the process to create a new table can be initiated, which will allow to upload the jar to /FileStore/tables
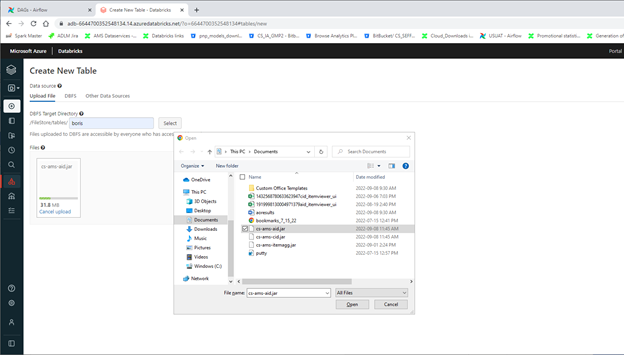
if needed the files can be copied from /FileStore/tables location to any other in dbfs using dbutils in databricks notebook:
dbutils.fs.cp("dbfs:/FileStore/tables/Boris/my.jar","dbfs:/FileStore/jars/Boris/my.jar")