Pytest testing of Cloud code on the personal laptop
Install JDK
Install Python Plugin
Install winutils
handling imports of pyspark.dbutils in non cloud environment
Create pytestSpark project in Intellij
Code conftest.py
Code firstload.py
Code TEST_firstLoad.py
Run the test
Test a single statement SQL Script
Install appropriate JDK
- create a project with the JDK needed and use the download jdk button to obtain the required JDK.
The JDK will later be used in the python project to test the hive/spark connection code
Select the Download
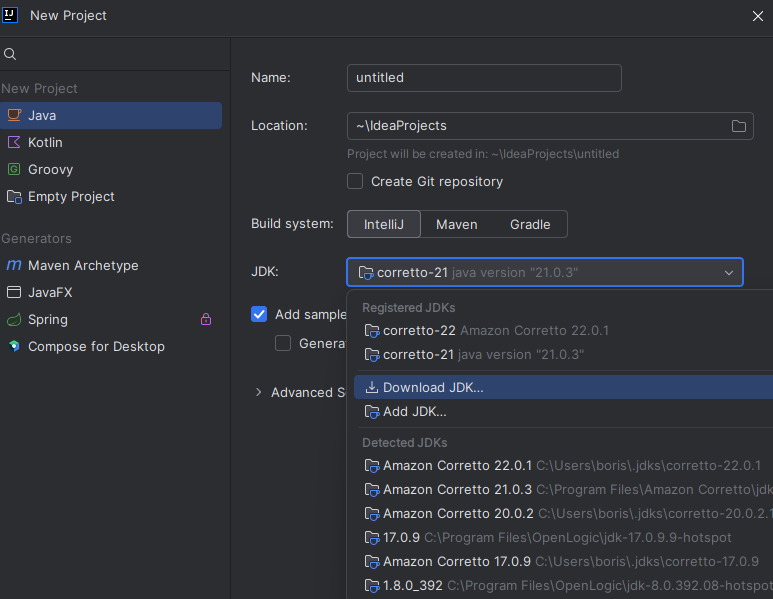
Select the version of JDK needed for testing
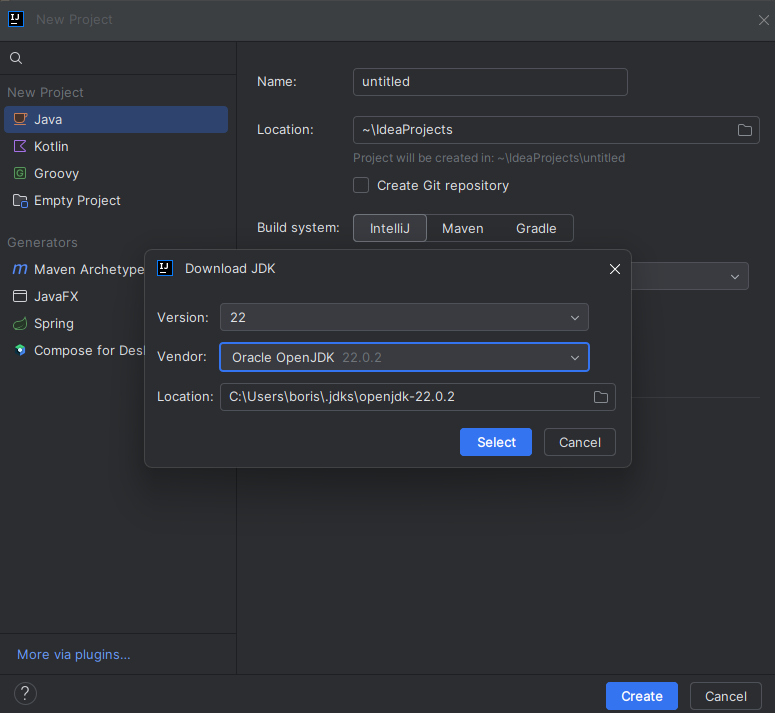
Install Python plugin
- Install plugin from MarketPlace to be able to work with Python projects in Intellij
Select Settings,Plugins and find Python plugin for Community Edition
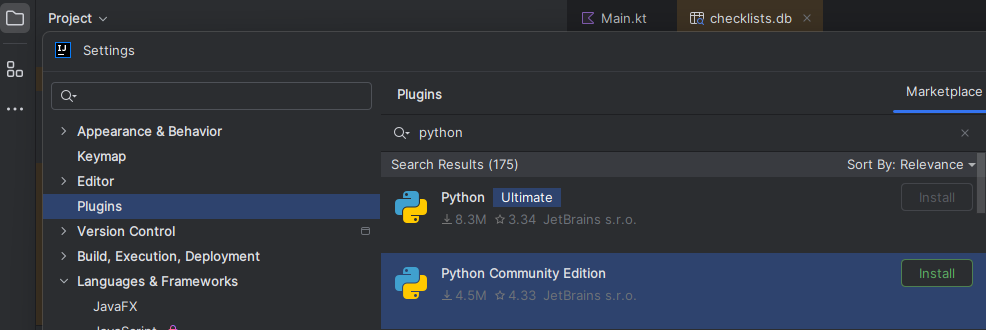
- Now it is possible to create a Python project
Install winutils
To simulate hive and hadoop filesystem on your personal laptop a winutils could be used
- clone repository https://github.com/cdarlint/winutils.git
Select the current version of hadoop (3.2.1 is matching databricks system)
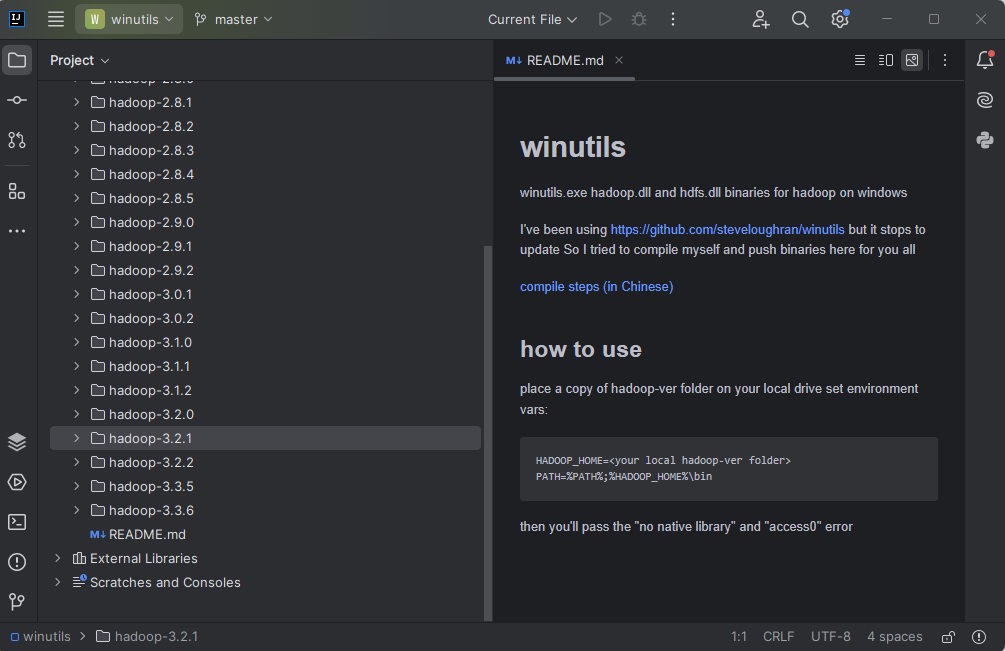
- copy the directory to your file system, e.g. C:\hadoop.3.2.1, and rename it to hadoop
- Set the hadoop variables to point to the hadoop directory
HADOOP_HOME=C:\hadoop
set HADOOP_USER_CLASSPATH=true
set HIVE_HOME=C:\hadoop\bin
set HIVE_BIN=C:\hadoop\bin
set HIVE_LIB=C:\hadoop\bin
Add the HADOOP_HOME to PATH, set PATH=C:\hadoop\bin;%PATH
Handling imports of pyspark.dbutils in non cloud environment
When the development code contains the direct import of pyspark.dbutils the module can be replaced by a fixture intest.
- create a class DBUtilsFixture with all the methods of dbutils you need to use in the test
- Add the following lines of code to override the module with the one you have created
module=type(sys)('pyspark')
module.dbutils=DBUtilsFixture
sys.modules['pyspark.dbutils']=module.dbutils
Create pytestSpark project in Intellij
- Create a directory structure and put the files in place:
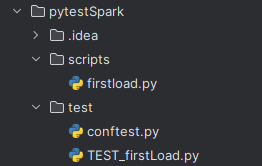
-
Code conftest.py
import sys
import pytest
from pyspark.sql import SparkSession
from pyspark import errors
from dataclasses import dataclass
@dataclass
class DBUtilsFixture:
def __init__(self):
self.fs = self
self.fs.rm = self
def __call__(self,path,flag):
return DBUtilsFixture
def fs(self):
def rm(self,path,flag):
return True
__call__ = rm
def DBUtils(self,SparkSession):
return DBUtilsFixture()
module = type(sys)('pyspark')
module.dbutils = DBUtilsFixture()
sys.modules['pyspark.dbutils'] = module.dbutils
@pytest.fixture(scope="session")
def sparkSession():
spark = (SparkSession.builder
.config("spark.sql.catalogImplementation","hive")
.config("spark.sql.legacy.createHiveTableByDefault","false")
.appName("TestSpark")
.getOrCreate())
yield spark
spark.stop()
@pytest.fixture(scope="session")
def createTestDB(sparkSession):
sparkSession.sql("Create database if not exists testdb_src location'data/testdb_src'")
sparkSession.sql("Create database if not exists testdb_trg location'data/testdb_trg'")
createSourceTables(sparkSession)
def createSourceTables(sparkSession):
sparkSession.sql("drop table if exists testdb_src.table1")
sparkSession.sql("create table testdb_src.table1(id int,name string)")
sparkSession.sql("insert into testdb_src.table1 values (1,'Main junction')")
sparkSession.sql("insert into testdb_src.table1 values (2,'Nuclear unicorns')")
-
Code firstload.py
import pyhocon
def runTransformation(conf,spark):
for key in conf.keys():
if not isinstance(conf.get(key),pyhocon.config_tree.ConfigTree):
spark.sql("set hivevar:{0} = {1}".format(key,conf.get(key)))
strSQL = """insert into ${src_db}.table1
values(2,'inserted value')
"""
spark.sql(strSQL)
-
Code TEST_firstLoad.py
from pyhocon import ConfigFactory
import os,sys
sys.path.insert(0,"")
import findspark
findspark.init()
from pytestSpark.scripts.firstload import runTransformation
def test_transformation(sparkSession,createTestDB):
test_conf = {"src_db":"testdb_src","trg_db":"testdb_trg"}
print("Starting the test execution")
runTransformation(ConfigFactory.from_dict(test_conf),sparkSession)
assert sparkSession.sql("select * from testdb_src.table1").count() == 3
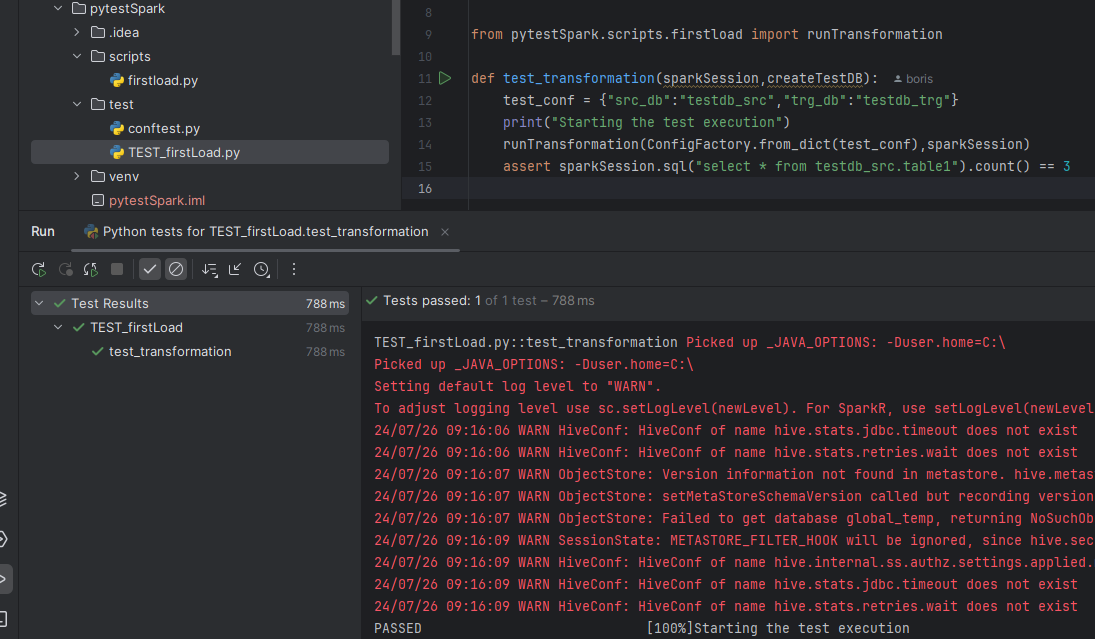
Run the test
Run the test by clicking the green triangle in the TEST_firstLoad.py by the test_transformation definition
Test a single statement SQL Script
- Create an SQL script in the scripts folder:
populate.sql
insert into ${src_db}.table1 values(27,'SQL inserted value');
- Create a python script in the test folder:
TEST_sqlscript.py
import jinja2
from jinja2 import FileSystemLoader
def testSQL(sparkSession,createTestDB):
environment = jinja2.Environment(loader=FileSystemLoader("../scripts"),variable_start_string='${', variable_end_string='}')
test_conf = {"src_db":"testdb_src","trg_db":"testdb_trg"}
filename = "populate.sql"
print("//////////// Execution of a single statement script ///////////////")
template = environment.get_template(filename)
scriptContent = template.render(test_conf)
print(scriptContent)
sparkSession.sql(scriptContent)
assert sparkSession.sql("select id,name from testdb_src.table1").count() >= 3
- Run the TEST_sqlscript.py by clicking the green triangle
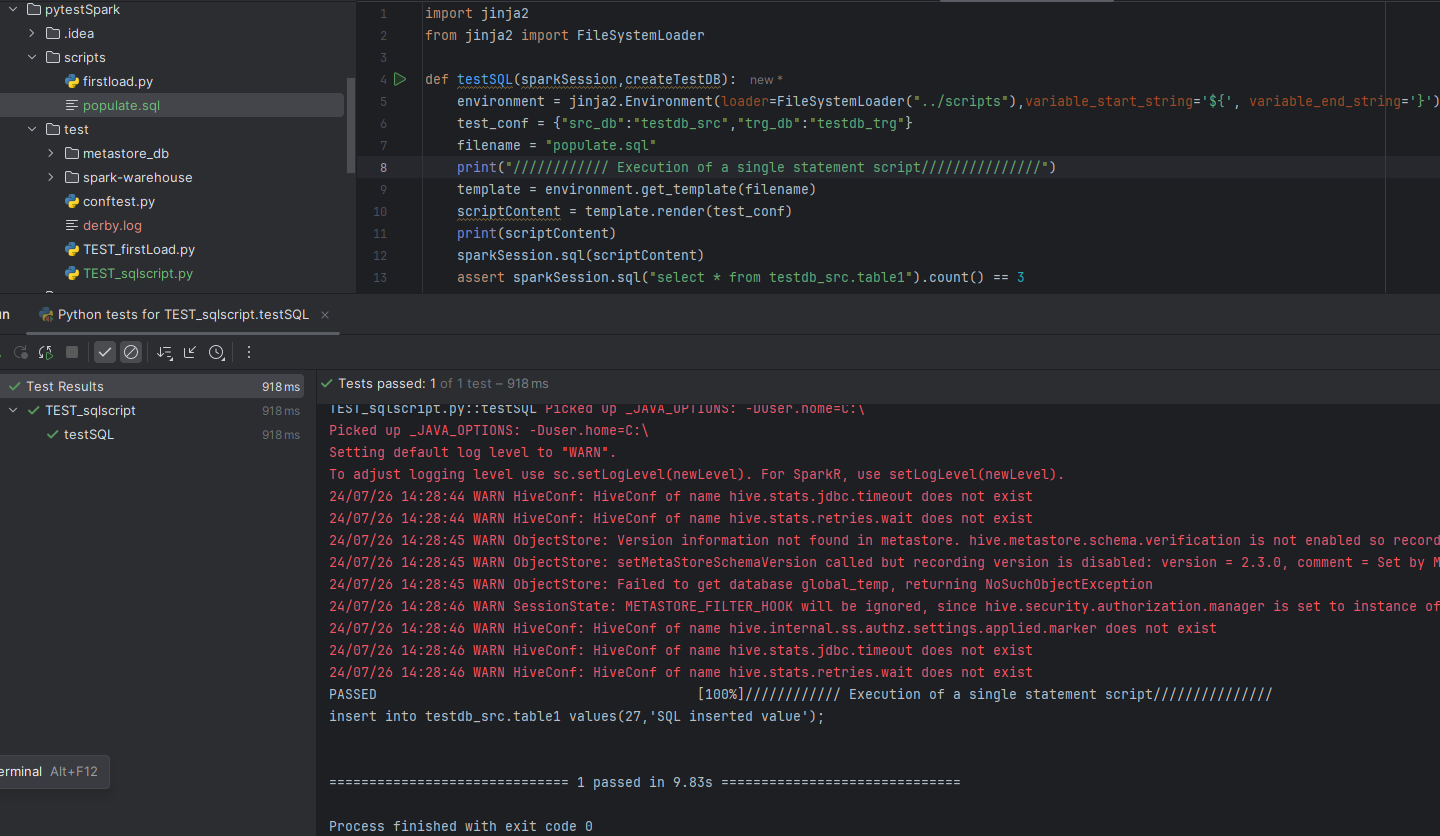
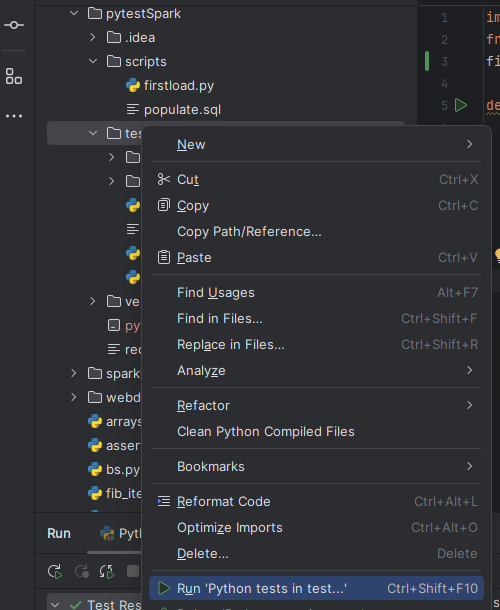
- Run multiple tests in folder
right click the tests directory and select "Run Python tests in test"
Test results:
