- Install software
- update configuration files
- create metastore database
- set the environment variables
- update hive-site.xml to use metastore database
- run schematool
- start the hiveserver2
- start the metastore
- verify installation from hive and beeline
- creating a user database
- check the HiveServer2 WebUI
- set the backup of the metastore database
- command line postgress metastore db backup/restore
- Loss/corruption of metastore database resiliency
Install software
download apache-hive-3.1.2-bin.tar.gz from apache hive site and put it into /data2 directory at namenode1
ssh namenode1
su
groupadd hive
useradd -g hive hive
usermod -a -G hadoop hive
passwd hive
cd /app
tar -xzvf /data2/apache-hive-3.1.2-bin.tar.gz -C /app/
mv apache-hive-3.1.2-bin hive
[root@namenode1 app]# chmod -R 755 hive
[root@namenode1 app]# chown -R hive:hive hive
su - hdfs
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -chmod -R 775/user/hive/warehouse
hdfs dfs -chown -R hive:hadoop /user/hive
hdfs dfs -mkdir /tmp
hdfs dfs -chmod -R 777 /tmp
update configuration files
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode2:8020</value>
</property>
<property>
<name>hadoop.proxyuser.hive.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hive.hosts</name>
<value>*</value>
</property>
</configuration>
create metastore database
login into r02edge(where the postgresql instance is running)
su - postgres
psql
create a new user:
create role hive with login password 'sOmePasWD' valid until 'infinity';
create a database for metastore:
create database hivemetastoredb with encoding='UTF8' owner=hive connection limit=-1;
grant all privileges:
grant all privileges on database hivemetastoredb to hive;
If you need to drop the old version of the database then sessions need to killed:
postgres-# select pg_terminate_backend(pid)
postgres-# from pg_stat_activity
postgres-# where pid in (select pid from pg_stat_activity where datname='hivemetastoredb');
drop database hivemetastoredb;
set the environment variables
get back to namenode1:
su - hive
vi .bashrc
export HIVE_HOME=/app/hive
export HADOOP_HOME=/app/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:${HIVE_HOME}/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export CLASSPATH=${CLASSPATH}:${HIVE_HOME}/lib:${HADOOP_HOME}/share/hadoop/common/lib
export LD_LIBRARY_PATH=${HADOOP_COMMON_LIB_NATIVE_DIR}:${LD_LIBRARY_PATH}
alias ls=ls
cd /app/hive/conf
update hive-site.xml to use metastore database
vi hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.postgresql.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:postgresql://192.168.2.30:5432/hivemetastoredb</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>MySecretPassWord</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>true</value>
</property>
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<property>
<name>hive.metastore.port</name>
<value>9083</value>
</property>
<property>
<name>mapreduce.input.fileinputformat.input.dir.recursive</name>
<value>true</value>
</property>
</configuration>
run schematool
to avoid Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
cd /app/hive/lib
rm guava-19.0.1.jar
cp /app/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar .
schematool -dbType postgres -initSchema -passWord pwdMyne -userName hive hivemetastoredb
Metastore connection URL: jdbc:postgresql://192.168.2.30:5432/hivemetastoredb
Metastore Connection Driver : org.postgresql.Driver
Metastore connection User: hive
Starting metastore schema initialization to 3.1.0
Initialization script hive-schema-3.1.0.postgres.sql
Initialization script completed
schemaTool completed
start the hiveserver2
[hive@namenode1 ~]$ mkdir hiveserver2log
[hive@namenode1 ~]$ cd hiveserver2log
[hive@namenode1 hiveserver2log]$ nohup hive --service hiveserver2 1>hiveserver2.log 2>hiveserver2.err &
[1] 1380
start the metastore
[hive@namenode1 ~]$ mkdir hivesmetastorelog
[hive@namenode1 ~]$ cd hivesmetastorelog
[hive@namenode1 hiveserver2log]$ nohup hive --service metastore &
the thrift server will start at port 9083 of namenode1:
[hive@namenode1 hivemetastorelog]$ lsof -i:9083
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 3857 hive 501u IPv4 172707 0t0 TCP *:emc-pp-mgmtsvc (LISTEN)
java 3857 hive 502u IPv4 170604 0t0 TCP namenode1.custom-built-apps.com:emc-pp-mgmtsvc->r02edge.custom-built-apps.com:33228 (ESTABLISHED)
[hive@namenode1 hivemetastorelog]$ netstat -n | grep 9083
tcp 0 0 192.168.2.25:9083 192.168.2.30:33228 ESTABLISHED
verify installation from hive and beeline
hive --version
Hive 3.1.2
Git git://HW13934/Users/gates/tmp/hive-branch-3.1/hive -r 8190d2be7b7165effa62bd21b7d60ef81fb0e4af
hive
create database dataexplorer1;
exit;
su - hdfs
hdfs dfs -chown dataexplorer1:hadoop /hive/warehouse/dataexplorer1.db
hdfs dfs -chown -R dataexplorer1:hadoop /tmp/hadoop-yarn/staging/dataexplorer1
su - dataexplorer1
hive
use dataexplorer1;
create table hosts(id integer,hostname string);
insert into hosts values(1,'namenode1.custom-built-apps.com')
select * from hosts;
OK
1 namenode1.custom-built-apps.com
Time taken: 4.911 seconds, Fetched: 1 row(s)
exit;
beeline -u jdbc:hive2://namenode1:10000/dataexplorer1 -n dataexplorer1
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://> select * from dataexplorer1.hosts;
OK
+-----------+----------------------------------+
| hosts.id | hosts.hostname |
+-----------+----------------------------------+
| 1 | namenode1.custom-built-apps.com |
+-----------+----------------------------------+
1 row selected (5.829 seconds)
create a script : beeline_cba
#!/bin/sh
beeline -u jdbc:hive2://namenode1:10000/dataexplorer1 -n ${USER}
creating a user database
su - dataexplorer1
beeline_cba
create database mydb location '/user/dataexplorer1/mydb';
use mydb;
create table mydb.mytab(id string);
insert into mydb.mytab values('first insert');
if spark is installed :
spark-sql
insert into hosts values(2,'namenode2.custom-built-apps.com')
this is a faster approach then changing hive engine to spark
moreover if the beeline is not needed, there is no need to start hiveserver2, in version 3 hivemetastore is a standalone package and this is all that spark needs to connect to the underlying tables.
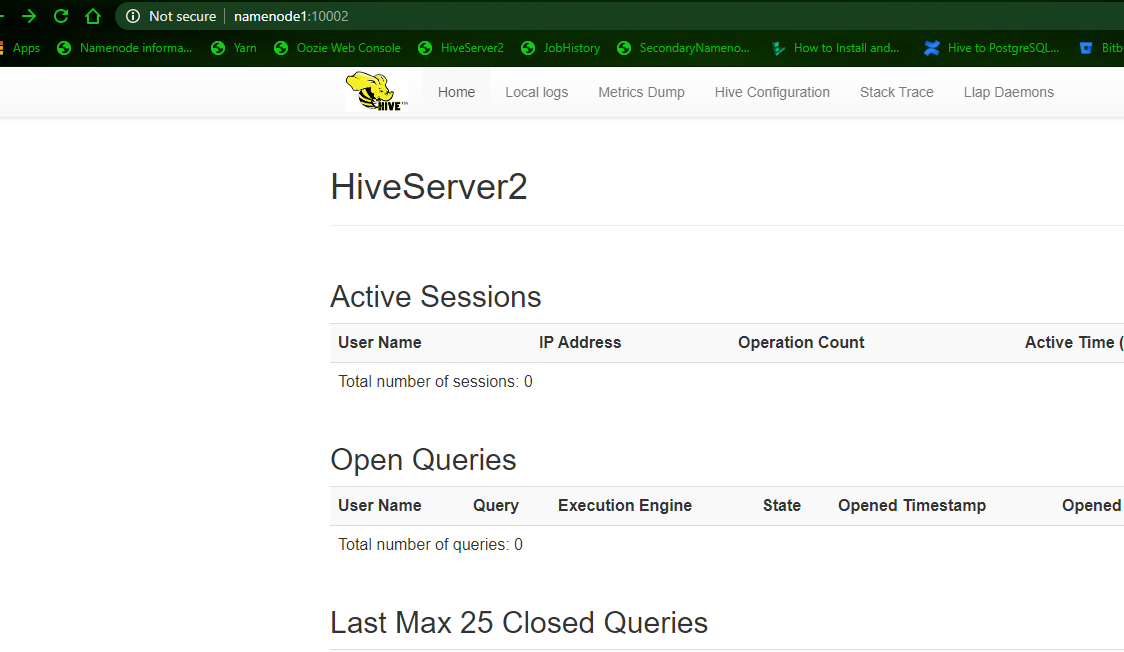
check the HiveServer2 WebUI
http://namenode1.custom-built-apps.com:10002
set the backup of the metastore database
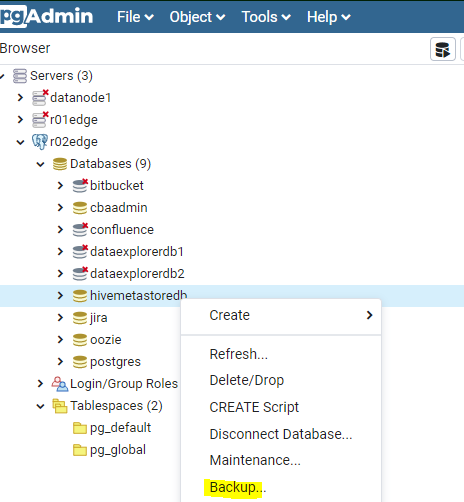
command line postgress metastore db backup/restore
su - hive
vi $HOME/.pgpass
r02edge:5432:hivemetastoredb:hive:PaSSword_here
mkdir backups
cd backups
pg_dump -F c -b -v -f hivemetastoredb.backup_080320202 hivemetastoredb
the database can be restored using psql:
psql hivemetastoredb <hivemetastoredb.backup_080320202
Loss/corruption of metastore database resiliency
tables creation process must be resilient to the loss of metastore database.
the approach is:
- create a hive database
- create the tables as external
- keep the table creation scripts
- if the metastore database cannot be restored→ recreate the database
- run the schematool to recreate the metastore database
- run the table creation scripts, the data in external tables will not be lost in case of metastore loss.
- verify the metastrore tbls table contain all the tables metadata.