Prerequisites
1. Complete installation of OS as per Operating system installation for Hadoop
2. Install JDK
#pdsh -w datanode[1-5] yum -y install java-1.8.0-openjdk-devel
#java -version
openjdk version "1.8.0_252"
OpenJDK Runtime Environment (build 1.8.0_252-b09)
OpenJDK 64-Bit Server VM (build 25.252-b09, mixed mode)
# javac -version
javac 1.8.0_252
3. add hadoop group
vi /etc/group
hadoop:x:4000
4. add users hdfs and yarn in hadoop group
useradd -g hadoop hdfs
passwd hdfs
useradd -g hadoop yarn
passwd yarn
vi /etc/passwd
hdfs:x:4001:4000::/home/hdfs:/bin/bash
yarn:x:4002:4000::/home/yarn:/bin/bash
chown -R hdfs /home/hdfs
chown -R yarn /home/yarn
5. create passwordless ssh for hdfs and yarn users
su - hdfs
ssh-keygen -b 4096
cd ~/.ssh
cp id_rsa.pub master.pub
cp master.pub authorized_keys
Verify it is possible to login without password
ssh localhost
the files master.pub and authorized_keys should be copied into /home/hdfs/.ssh/ of every node in the cluster
6. copy software to all the nodes
all the dowloaded software is residing in /data2/software directory
scp -r software r02edge:/data2
scp -r software datanode1:/data2
Installation
- Plan the installation by listing all the nodes of the future cluster
Namenodes: namenode1, namenode2
Datanodes: datanode1,datanode2,datanode3,datanode4,datanode5
Edge nodes: r01edge, r02edge
2. Untar the hadoop installation at namenode1 and rename the directory
tar -C /home/hdfs -xzvf /data2/software/hadoop-3.2.1.tar.gz
mv hadoop-3.2.1 hadoop
3. Untar the hadoop installation as hdfs user to all the nodes and rename the directory
pdsh -w namenode2,datanode[1-5],r0[1-2]edge tar -C /home/hdfs -xzvf /data2/software/hadoop-3.2.1.tar.gz
pdsh -w namenode2,datanode[1-5],r0[1-2]edge mv /home/hdfs/hadoop-3.2.1 /app/hadoop
Configuration
1.Plan the configuration of namenodes,resource manager,datanodes
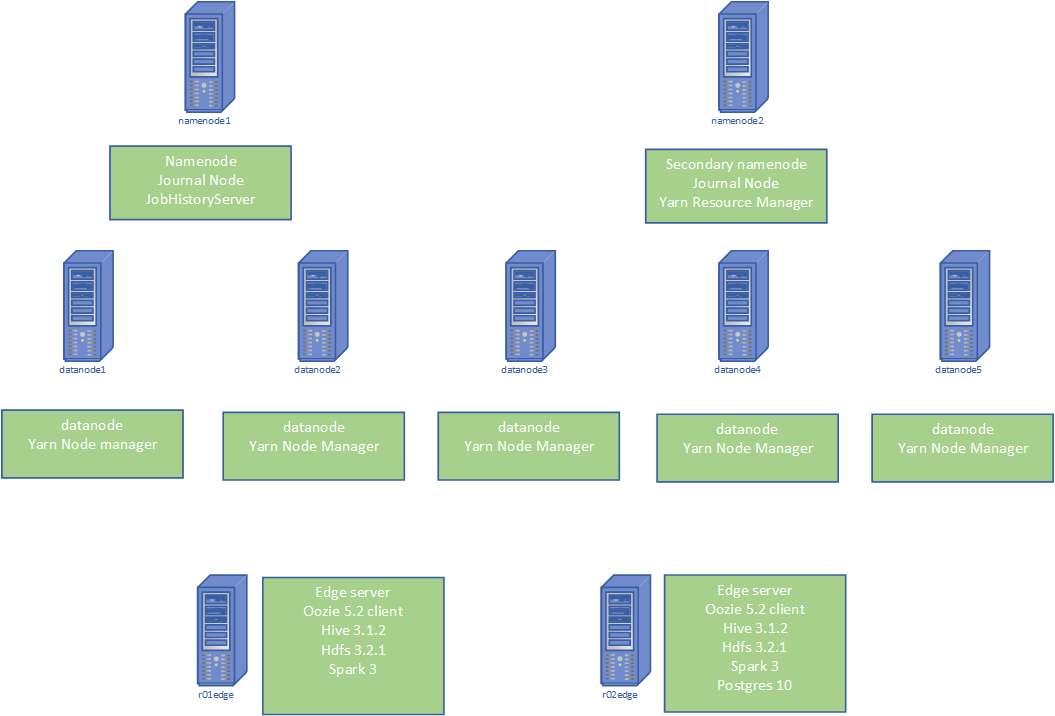
2. Configure hadoop at namenode1 and then push the configuration files to all the nodes
vi .bashrc
export HADOOP_HOME=/app/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export LD_LIBRARY_PATH=${HADOOP_COMMON_LIB_NATIVE_DIR}:${LD_LIBRARY_PATH:-}
copy the configured directory to all the other nodes:
[hdfs@namenode1 ~]$ pdsh -w namenode2,datanode[1-5],r0[1-2]edge scp -r namenode1:/app/hadoop/etc/hadoop/* /app/hadoop/etc/hadoop/
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode2:8020</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>hdfs</value>
</property>
</configuration>
hdfs-site.xml (namenode)
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data1/dfs/nn,file:///data2/dfs/nn</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>namenode2.custom-built-apps.com</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>81920</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data1/dfs/nm</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
Datanodes:
The hdfs-site.xml differs at the datanodes.
datanode1,datanode2 have 4 data directories
datanode3,datanode5 have 3 data directories
datanode4 has 2 datadirectories
this call for different entries in dfs.datanode.data.dir value
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data1/dfs/nn,file:///data2/dfs/nn</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data1/dfs/dn,file:///data2/dfs/dn,file:///data3/dfs/dn,file:///data4/dfs/dn</value>
</property>
</configuration>
Initializing hadoop
ssh namenode2
su - hdfs
note: this will clear the existing cluster, exercise caution
hdfs dfs -format cbacluster1
Starting hadoop
hdfs --daemon start namenode
each datanode:
hdfs --daemon start datanode
hdfs dfsadmin -report
hdfs dfs -mkdir /share
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/dataexplorer1
hdfs dfs -mkdir /user/dataexplorer2
hdfs dfs -chown -R dataexplorer1 /user/dataexplorer1
hdfs dfs -chown -R dataexplorer2 /user/dataexplorer2
hdfs dfs -chmod 755 /user/dataexplorer1
hdfs dfs -chmod 755 /user/dataexplorer2
hdfs dfs -chmod 775 /share
hdfs dfs -mkdir /tmp
hdfs dfs -chown mapred:mapred /tmp
hdfs dfs -chmod 777 /tmp
copy .bashrc from hdfs to dataexplorer1
change dataexplorer1 group to hadoop
put a file in hdfs:
vi animals:
cat
leopard
dog
mad dog
prairy dog
cat woman
a woman with a leopard
[dataexplorer1@r02edge ~]$ vi animals
[dataexplorer1@r02edge ~]$ hdfs dfs -put animals
hdfs dfs -ls
start secondary node at namenode1:
hdfs --daemon start secondarynamenode
jps
Hadoop web interface:
http://namenode2.custom-built-apps.com:9870/dfshealth.html#tab-overview

Datanodes information:
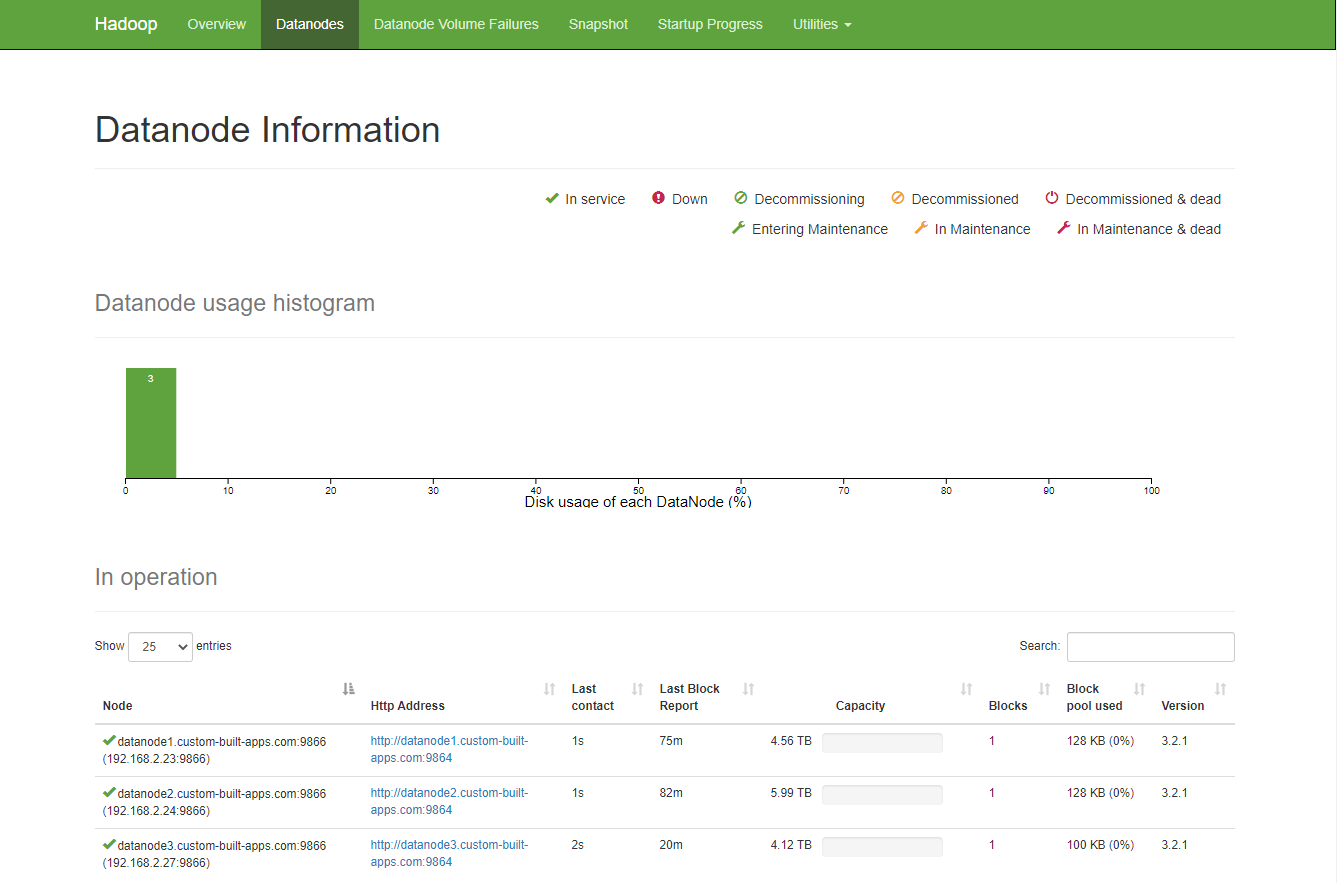
start job history server at namenode1:
hdfs dfs -mkdir -p /tmp/hadoop-yarn/staging/history/done
hdfs dfs -chown -R mapred /tmp/hadoop-yarn
hdfs dfs -chmod -R 775 /tmp/hadoop-yarn
su - mapred
mapred --daemon start historyserver
jps
cd /var/log/hadoop/mapred
check the latest log for errors
Job history web interface:
http://namenode1.custom-built-apps.com:19888/jobhistory
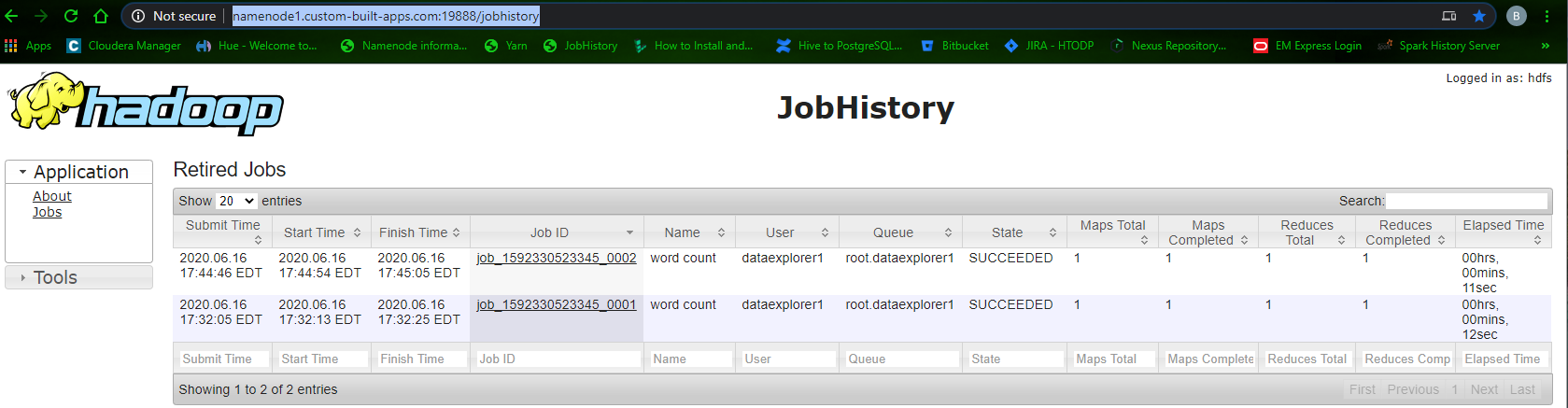
Starting Yarn
ssh namenode2
su - yarn
yarn --daemon start resourcemanager
on every node :
yarn --daemon start nodemanager
For a nodemanager to succesfully run and be seen by the resourcemanager:
- a local directory has to exist /data1/dfs/nm (mentioned in yarn-site.xml)
- the memory should be set in yarn-site.xml
yarn node -list:

Web interface:
http://namenode2.custom-built-apps.com:8088/cluster/nodes
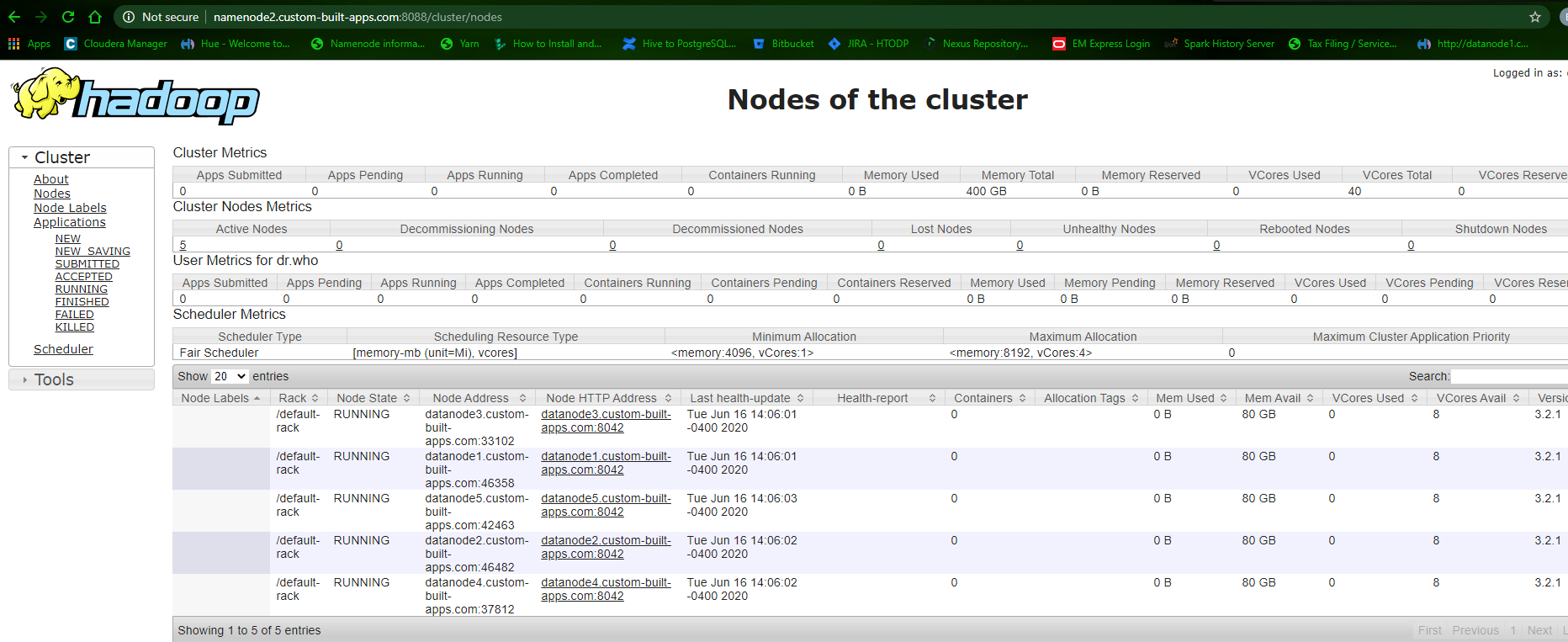
submit a word count program to yarn
yarn jar /app/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount animals anim_out
hdfs dfs -cat anim_out/*
a 2
cat 2
dog 3
leopard 2
mad 1
prairy 1
with 1
woman 2
add profile to /etc/profile.d/hadoop.sh for all users on all nodes:
vi /etc/profile.d/hadoop.sh
export HADOOP_HOME=/app/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export JAVA_HOME=${JAVA_HOME:-"/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-2.el7_8.x86_64"}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"${HADOOP_HOME}/etc/hadoop"}
export LD_LIBRARY_PATH=${HADOOP_HOME}/lib/native:${LD_LIBRARY_PATH}
Starting job history server
[root@namenode1 /var/run] mkdir -p /var/run/hadoop/mapred
chown mapred:hadoop /var/run/hadoop/mapred
chown hdfs:hadoop /var/run/hadoop
chmod 775 /var/run/hadoop
su - mapred
mapred --daemon start historyserver
http://namenode1.custom-built-apps.com:19888/jobhistory
High Availability(NOT IMPLEMENTED):
hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>cbacluster1</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cbacluster1</value>
</property>
<property>
<name>dfs.ha.namenodes.cbacluster1</name>
<value>namenode1,namenode2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cbacluster1.namenode1</name>
<value>namenode1.custom-built-apps.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cbacluster1.namenode2</name>
<value>namenode2.custom-built-apps.com:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.cbacluster1.namenode1</name>
<value>namenode1.custom-built-apps.com:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.cbacluster1.namenode2</name>
<value>namenode2.custom-built-apps.com:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://datanode5.custom-built-apps.com:8485;datanode4.custom-built-apps.com:8485;datanode3.custom-built-apps.com:8485/cbacluster1</value>
</property>
<property> <name>dfs.journalnode.edits.dir</name> <value>/data1/hadoop/jn/data</value> </property>
<property>
<name>dfs.client.failover.proxy.provider.cbacluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hdfs/.ssh/id_rsa</value>
</property></configuration>
create directories:
#pdsh -w datanode3,datanode4,datanode5 mkdir -p /data1/hadoop/jn/data
# pdsh -w datanode3,datanode4,datanode5 chown -R hdfs:hadoop /data1/hadoop/jn/data
start journal nodes at datanode3, datanode4 datanode5:
hdfs --daemon start journalnode
format namenode2: not needed as it is being converted
initialize the edits directories from namenode2: hdfs namenode -initializeSharedEdits -force
bootstrap namenode1:hdfs namenode -bootstrapStandby -force
start the zookeper service on the Zookeper hosts: hdfs zkfc -formatZK -force
start namenode2, the only active currently : hdfs --daemon start namenode
start namenode1: hdfs --daemon start namenode
check the HA state of the servers:
hdfs haadmin -getServiceState namenode1
hdfs haadmin -getServiceState namenode2
hdfs haadmin -transitionToActive namenode1 --forcemanual
[hdfs@namenode2 ~]$ hdfs haadmin -getServiceState namenode2
standby
[hdfs@namenode2 ~]$ hdfs haadmin -getServiceState namenode1
standby
Creating snapshots of directories
- Allow creating snapshots:
[hdfs@namenode2 ~]$ hdfs dfsadmin -allowSnapshot /user/dataexplorer1/dataexplorer1.db
Allowing snapshot on /user/dataexplorer1/dataexplorer1.db succeeded
[hdfs@namenode2 ~]$ hdfs dfsadmin -allowSnapshot /user/dataexplorer1/databasetables
Allowing snapshot on /user/dataexplorer1/databasetables succeeded - Verify as user you have snapshottable directories:
[dataexplorer1@r01edge ~]$ hdfs lsSnapshottableDir
drwxrwxr-x 0 dataexplorer1 hadoop 0 2021-06-29 14:04 1 65536 /user/dataexplorer1/databasetables
drwxr-xr-x 0 dataexplorer1 hadoop 0 2021-06-29 14:04 1 65536 /user/dataexplorer1/dataexplorer1.db - Create snapshots:
[dataexplorer1@r01edge ~]$ hdfs dfs -createSnapshot /user/dataexplorer1/databasetables
Created snapshot /user/dataexplorer1/databasetables/.snapshot/s20210629-140408.924
[dataexplorer1@r01edge ~]$ hdfs dfs -createSnapshot /user/dataexplorer1/dataexplorer1.db
Created snapshot /user/dataexplorer1/dataexplorer1.db/.snapshot/s20210629-140438.120 - Rename snapshots:
[dataexplorer1@r01edge ~]$ hdfs dfs -renameSnapshot /user/dataexplorer1/databasetables s20210629-140408.924 initialSnap
[dataexplorer1@r01edge ~]$ hdfs dfs -ls /user/dataexplorer1/databasetables/.snapshot/
Found 1 items
drwxrwxr-x - dataexplorer1 hadoop 0 2021-06-29 14:04 /user/dataexplorer1/databasetables/.snapshot/initialSnap - Create a new subdirectory and create a snapshot:
[dataexplorer1@r01edge ~]$ hdfs dfs -mkdir /user/dataexplorer1/databasetables/aNewDir
[dataexplorer1@r01edge ~]$ hdfs dfs -cp /user/dataexplorer1/databasetables/hosts/* /user/dataexplorer1/databasetables/aNewDir/
[dataexplorer1@r01edge ~]$ hdfs -createSpapshot /user/dataexplorer1/databasetables secondSnap - Verify the difference between the snapshots:
[dataexplorer1@r01edge ~]$ hdfs snapshotDiff /user/dataexplorer1/databasetables initialSnap secondSnap
Difference between snapshot initialSnap and snapshot secondSnap under directory /user/dataexplorer1/databasetables:
M .
+ ./aNewDir - Delete the new directory and restore it from snapshot:
[dataexplorer1@r01edge ~]$ hdfs dfs -rm -r -skipTrash /user/dataexplorer1/databasetables/aNewDir
Deleted /user/dataexplorer1/databasetables/aNewDir
[dataexplorer1@r01edge ~]$ hdfs dfs -cp -ptopax /user/dataexplorer1/databasetables/.snapshot/secondSnap/aNewDir /user/dataexplorer1/databasetables/
2021-06-29 14:35:19,495 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2021-06-29 14:35:19,576 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
[dataexplorer1@r01edge ~]$ hdfs dfs -ls /user/dataexplorer1/databasetables/aNewDir
Found 1 items
-rw-r--r-- 3 dataexplorer1 hadoop 275 2021-06-29 14:19 /user/dataexplorer1/databasetables/aNewDir/hosts.csv