download spark-3.0.0-bin-hadoop3.2.tgz from spark downloads.
untar the tarbal
cd /app
tar -xzvf /data2/software/spark-3.0.0-bin-hadoop3.2.tgz
mv spark-3.0.0-bin-hadoop3.2. spark
SPARK_HOME=/app/spark
copy hive-site.xml from $HIVE_HOME/conf to $SPARK_HOME/conf
add metastore location to hive-site.xml
hive-site.xml
<property>
<name>hive.metastore.uris</name>
<value>thrift://namenode1:9083</value>
</property>
vi /app/spark/conf/spark-defaults.conf
spark.master yarn
spark.deploy-mode cluster
spark.yarn.submit.waitAppCompletion true
spark.eventLog.enabled true
spark.eventLog.dir hdfs://namenode1:8020/tmp/sparkEventLogs
spark.yarn.jars hdfs://namenode1:8020/spark-jars/*
create directories in hdfs:
su - hdfs
mkdir /tmp/sparkEventLogs
mkdir /spark-jars
chown spark:hadoop /tmp/sparkEventLogs
chown spark:hadoop /spark-jars
su - spark
replace the guava jar to match hadoop and hive:
cd /app/spark/jars
rm -rf guava-14.0.1.jar
[spark@namenode1 jars]$ cp /app/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar .
Copy the jars to hdfs
hdfs dfs -put /app/spark/jars/* /spark-jars/
update .bashrc
export HIVE_HOME=/app/hive
export SPARK_HOME=/app/spark
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:${HIVE_HOME}/bin:${SPARK_HOME}/bin
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export CLASSPATH=${HIVE_HOME}/lib/*:$HADOOP_HOME/share/common/hadoop/lib/*:${CLASSPATH}
spark-shell
Spark context available as 'sc' (master = yarn, app id = application_1592330523345_0015).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 1.8.0_252)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.sql("show databases").show(false)
2020-06-17 21:20:11,247 WARN conf.HiveConf: HiveConf of name hive.metastore.local does not exist
+-------------+
|namespace |
+-------------+
|dataexplorer1|
|default |
+-------------+
scala> spark.sql("show tables in dataexplorer1")
res1: org.apache.spark.sql.DataFrame = [database: string, tableName: string ... 1 more field]
scala> res1.show(false)
+-------------+---------+-----------+
|database |tableName|isTemporary|
+-------------+---------+-----------+
|dataexplorer1|hosts |false |
|dataexplorer1|mytab |false |
|dataexplorer1|testing |false |
+-------------+---------+-----------+
scala> spark.sql("select * from dataexplorer1.hosts")
res3: org.apache.spark.sql.DataFrame = [id: int, hostname: string]
scala> res3.show(false)
+---+-------------------------------+
|id |hostname |
+---+-------------------------------+
|1 |namenode1.custom-built-apps.com|
+---+-------------------------------+
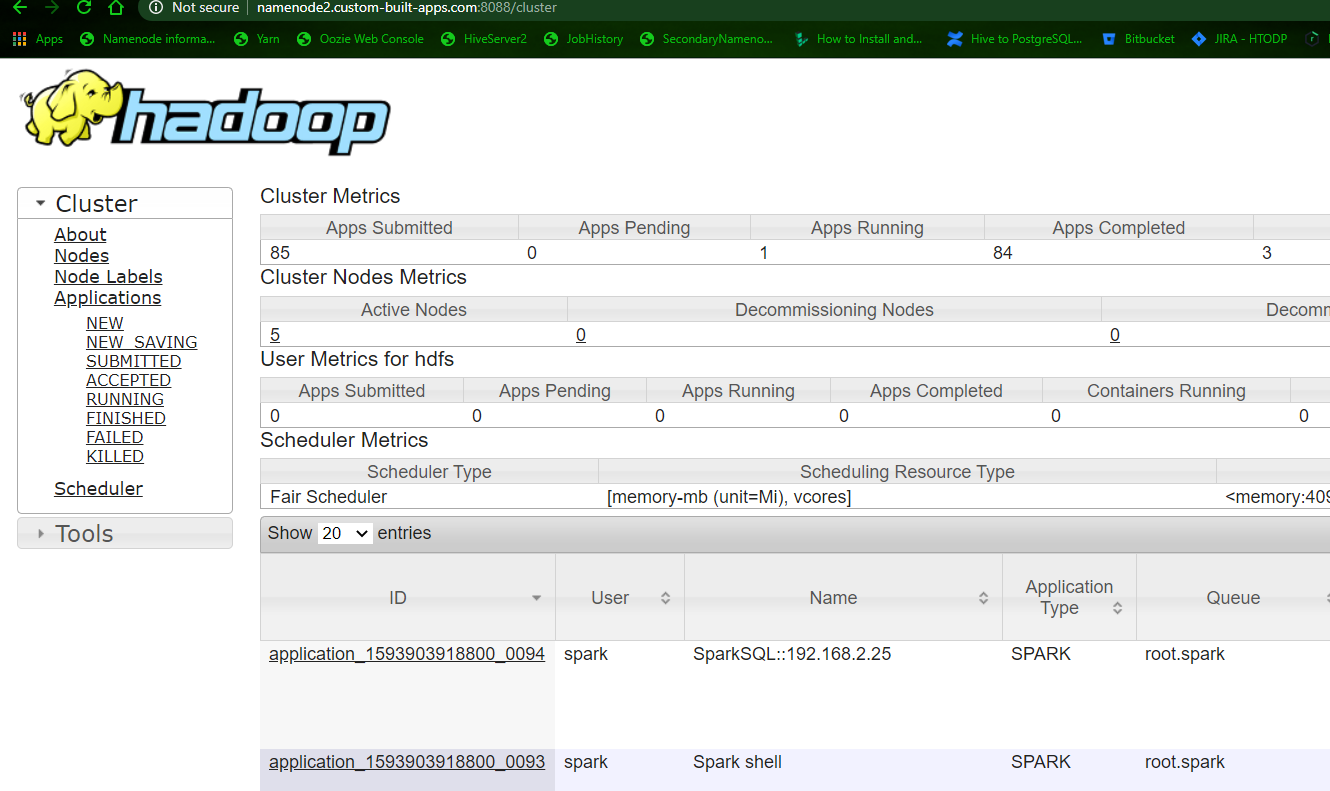
SPARK WEB UI while the shell is running at namenode1 is avaialable at
http://namenode1:4040, it will redirect to Yarn resource manager Web at http://namenode2.custom-built-apps.com:8088/

Yarn resource manager will show spark jobs:
spark-sql
show databases;
use dataexplorer1;
select * from bobtab;
insert into bobtab values(45,'futile');
select * from bobtab;
spark-submit --version
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0
/_/
Using Scala version 2.12.10, OpenJDK 64-Bit Server VM, 1.8.0_252
Branch HEAD
Compiled by user ubuntu on 2020-06-06T13:05:28Z
Revision 3fdfce3120f307147244e5eaf46d61419a723d50
Url https://gitbox.apache.org/repos/asf/spark.git
dependencies in pom.xml for Spark3 development should be updated:
<properties>
<encoding>UTF-8</encoding>
<scala.version>2.12.10</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
{kind=link}