overview
- the functionality to be tested is integrated execution of cbaWorkflow and cbaWFMonitor
- The data should be generated/prepared
- scripts need to be generated
- shell scripts,spark-sql scripts, spark-submit jars should be deployed into the directory pointed to by the RUN_DIR variable
- run.sh script should be deployed into the directory pointed to by the RUN_DIR variable
- nodes and adjacency lists information should be entered into the repository
- Application run should start in the ${RUN_DIR} directory
Testing schematics

Nodes
recreating OS directory - Shell node(single command)
generating OS files -Shell node (scripts)
put OS files to hdfs - Hdfs node
create External tables - Spark sql node
generating tables with the words distribution - Spark Submit node
store distributions in a single parititioned table - spark sql node
There are 31 work nodes, a start node and and end node.
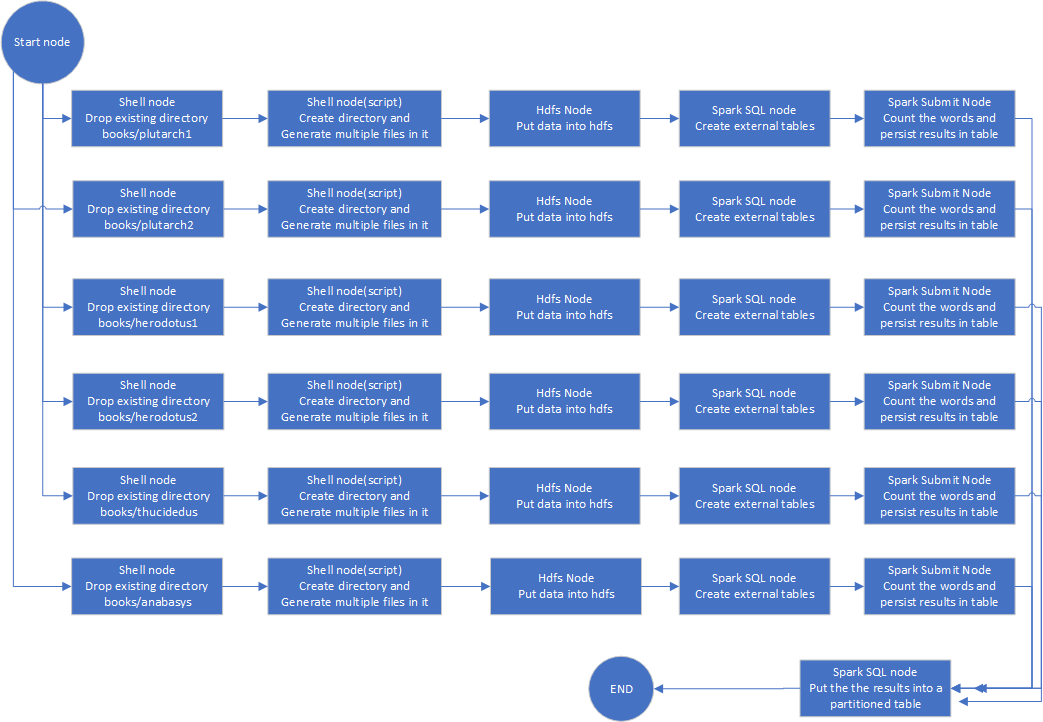
Testing graphs
starting the cbaWorkflow and cbaWFMonitor with 20 seconds difference to accommodate for the shared memory segment allocation
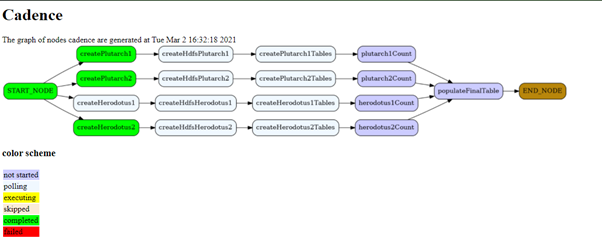
As seen from the diagram above while level one nodes have completed the level 2 and 3 nodes are polling.
Level 4 and 5 are intact. Level 3 started polling when the first node of level 1 has completed.
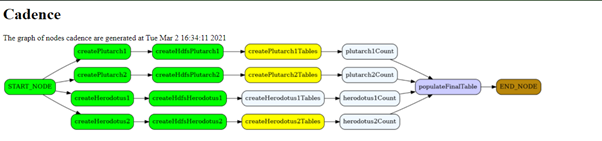
In the diagram above it can be observed that level 3 nodes are running, level 4 nodes are polling and level 5 is intact

Final diagram shows all the nodes completed and the end node changed its label to completed
Querying stats table
select n.node_id, n.name,nt.name as nodeType
,nes.start_time,nes.end_time,nes.run_time,nes.status
from nodes_execution_stats nes join nodes n on n.node_id=nes.node_id
join node_types nt on nt.node_type_id=n.node_type_id
where n.node_id not in ('0','99999')
order by start_time desc
| node_id | name | nodetype | start_time | end_time | run_time(sec) | status |
|---|---|---|---|---|---|---|
| 55 | populateFinalTable | sparkSQLNode | Tue Mar 2 16:42:28 2021 | Tue Mar 2 16:43:05 2021 | 37 | Success |
| 27 | herodotus1Count | sparkSubmitNode | Tue Mar 2 16:36:13 2021 | Tue Mar 2 16:41:36 2021 | 323 | Success |
| 25 | plutarch1Count | sparkSubmitNode | Tue Mar 2 16:35:13 2021 | Tue Mar 2 16:41:15 2021 | 362 | Success |
| 26 | plutarch2Count | sparkSubmitNode | Tue Mar 2 16:35:13 2021 | Tue Mar 2 16:41:08 2021 | 355 | Success |
| 28 | herodotus2Count | sparkSubmitNode | Tue Mar 2 16:35:13 2021 | Tue Mar 2 16:40:23 2021 | 310 | Success |
| 12 | createHerodotus1Tables | sparkSQLNode | Tue Mar 2 16:34:43 2021 | Tue Mar 2 16:35:18 2021 | 35 | Success |
| 10 | createPlutarch1Tables | sparkSQLNode | Tue Mar 2 16:33:43 2021 | Tue Mar 2 16:34:24 2021 | 41 | Success |
| 11 | createPlutarch2Tables | sparkSQLNode | Tue Mar 2 16:33:43 2021 | Tue Mar 2 16:34:21 2021 | 38 | Success |
| 13 | createHerodotus2Tables | sparkSQLNode | Tue Mar 2 16:33:43 2021 | Tue Mar 2 16:34:22 2021 | 39 | Success |
| 7 | createHdfsHerodotus1 | hdfsExecNode | Tue Mar 2 16:33:28 2021 | Tue Mar 2 16:33:57 2021 | 29 | Success |
| 5 | createHdfsPlutarch2 | hdfsExecNode | Tue Mar 2 16:32:28 2021 | Tue Mar 2 16:33:04 2021 | 36 | Success |
| 6 | createHerodotus1 | shellNode | Tue Mar 2 16:32:28 2021 | Tue Mar 2 16:32:47 2021 | 19 | Success |
| 3 | createHdfsPlutarch1 | hdfsExecNode | Tue Mar 2 16:32:28 2021 | Tue Mar 2 16:33:05 2021 | 37 | Success |
| 9 | createHdfsHerodotus2 | hdfsExecNode | Tue Mar 2 16:32:28 2021 | Tue Mar 2 16:32:59 2021 | 31 | Success |
| 2 | createPlutarch1 | shellNode | Tue Mar 2 16:31:28 2021 | Tue Mar 2 16:31:44 2021 | 16 | Success |
| 8 | createHerodotus2 | shellNode | Tue Mar 2 16:31:28 2021 | Tue Mar 2 16:31:43 2021 | 15 | Success |
| 4 | createPlutarch2 | shellNode | Tue Mar 2 16:31:28 2021 | Tue Mar 2 16:31:44 2021 | 16 | Success |
testing using cronjob
- Set all the environment variables in the run.sh script as cron environment is minimalistic:
export CBAWF_HOME=/home/dataexplorer1/cbaWorkflow
export SPARK_HOME=/app/spark
export SHELL=/bin/bash
export HADOOP_HOME=/app/hadoop
export PG_HOME=/usr/pgsql-10
export YARN_HOME=/app/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=/app/hadoop/lib/native
export MAIL=/var/spool/mail/dataexplorer1
export HADOOP_HDFS_HOME=/app/hadoop
export HIVE_HOME=/app/hive
export HADOOP_COMMON_HOME=/app/hadoop
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-2.el7_8.x86_64
export CBAWFINI=/home/dataexplorer1/.cbaWorkflow.ini
export HADOOP_INSTALL=/app/hadoop
export LANG=en_US.UTF-8
export HADOOP_CONF_DIR=/app/hadoop/etc/hadoop
export HADOOP_OPTS=-Djava.library.path=/app/hadoop/lib/native
export HOME=/home/dataexplorer1
export RUN_DIR=${HOME}/run
export YARN_CONF_DIR=/app/hadoop/etc/hadoop
export HADOOP_MAPRED_HOME=/app/hadoop
export CLASSPATH=/app/spark/jars/*:/app/hive/jdbc/*:/app/hive/lib/*:/app/tez/*:/app/tez/lib/*:
export LD_LIBRARY_PATH=/usr/local/lib64:${CBAWF_HOME}/lib:${LD_LIBRARY_PATH}
export PATH=/app/spark/bin:/app/hadoop/bin/:${RUN_DIR}:${CBAWF_HOME}/bin:${PATH}
export CBAWFINI=$HOME/.cbaWorkflow.ini
cd ${RUN_DIR}
nohup cbaWorkflowTest 1>cbaWorkflowTest.log 2>cbaWorkflowTest.err &
sleep 20
nohup cbaWFMonitorTest 1>cbaWFMonitorTest.log 2>cbaWFMonitorTest.err &
2. Add the line to cron file:
crontab -e
01 12 * * * sh /home/dataexplorer1/run/run.sh
testing skipped nodes

The graph above demonstrates that the nodes in the nodes_execution_schedule get excluded from execution
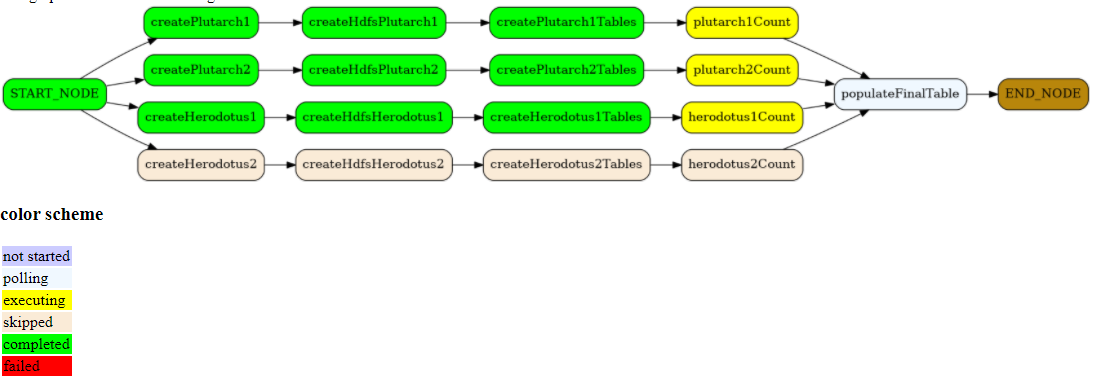
The node after the skipped ones starts and completes:
