this page is keeping track of development and maintenance of cbaWorklflow class
overview of tasks
cbaWorkflow does the following:
- reads repository tables into the memory structures
- creates a shared memory segment
- creates a shared memory semaphore
- creates a map of cbaWorkflowNodes, based on properties read from repository, map<node_Id,cbaWorkflowNodes*>
- creates an execution map in the shared memory for the created nodes
- creates a structure of levels of execution vector<vector<node_id>> based on adjacency List, generating adjacency matrix and calculating the levels
- starts the nodes as separate threads in the sequence of the levels of execution
- collects information about the nodes execution from shared memory and flag files and stores it in the repository
- restarts the failed nodes
- deletes memory of the completed nodes
- runs in a loop and starts nodes of the level N when the first node of level N-2 completed.
- collects execution logs
- dispatches notifications on start , completion the workflow and failures of the nodes
- cbaWorkflow completes successfully when the end node has completed its run
implementing class factory for cbaWorkflowNode
cbaWorkflow will be creating cbaWorkflowNode derived objects using the following paradigm, implementing the class factory pattern:
- Read the available node types and available implementation libraries from the repository
- Establish the kind of node to be created using the repository
- Load the library containing the implementation
- make a call to the libraries getClass function and retrieve a base class pointer (cbaWorkflowNode)
- populate the node using the information from the repository and the obtained pointer
- call the node's run() method in a separate thread
creating , initially updating and monitoring a node execution map in the shared memory segment
On initial load cbaWorkflow reads the repository and obtains the list of nodes participating in the execution using nodes_cadence table
before creating a vector of cbaWorkflowNodes cbaWorkflow creates a shared memory segment and puts a map<int,int> into it . The first value is a node ID, the second one is the execution status
cbaWorkflow creates a semaphore to protect the operations with the map
while creating a node cbaWorkflow passes the names of the shared memory segment, semaphore and map to each node
after the Nodes creation cbaWorkflow starts START_NODE and on completion it changes the START_NODE status from 0 to executed, thus effectively starting the run
Either Workflow or a Workflow monitor of cbaWorkflow saves the status of the map into the repository .
Workflow monitor of cbaWorkflow saves the status of the map into the repository once a specified period of time(1 minute is a ballpark)
starting the nodes
cbaWorkflow starts the nodes in levels, depending on the nodes cadence. The proposed algorithm is as follows:
- generate an adjacency matrix based on adjacency_lists table
- use vector[0] - the first row of the matrix to start the nodes(Level 1)
- create a dot product of the matrix by itself
- use the vector[0] of the matrix to start the nodes(Level 2)
- generate as many matrices as it takes until the end node is the only one left in the vector[0]
- use completion of a node in level N to start nodes of level N + 2
- Repeat the start node process in point 6 for all the levels
Given a sample nodes cadence chart and the nodes names and ids in repository, a sample POC application implementing this solution is provided:

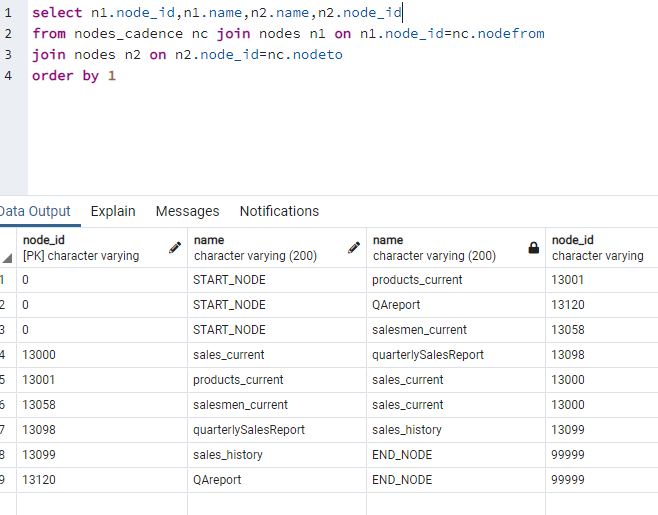
sample POC application in python:
#!/usr/local/bin/python3
import numpy as np
#create adjacency matrix
adjacency_matrix=np.array ([[0,0,1,1,0,0,1,0],
[0,0,0,0,1,0,0,0],
[0,1,0,0,0,0,0,0],
[0,1,0,0,0,0,0,0],
[0,0,0,0,0,1,0,0],
[0,0,0,0,0,0,0,1],
[0,0,0,0,0,0,0,1],
[0,0,0,0,0,0,0,0]
]);
print("adjacency matrix")
print(adjacency_matrix)
print("0,13000,13001,13058,13098,13099,13120,99999")
print("Initial start: Level 1")
print(adjacency_matrix[0])
print("Level 2 start")
level2=np.dot(adjacency_matrix,adjacency_matrix)
print(level2[0])
print("Level 3 start")
level3=np.dot(level2,adjacency_matrix)
print(level3[0])
print("Level 4 start")
level4=np.dot(level3,adjacency_matrix)
print(level4[0])
print("Level 5 start")
level5=np.dot(level4,adjacency_matrix)
print(level5[0])
/////////////////// OUTPUT////////////
adjacency matrix
[[0 0 1 1 0 0 1 0]
[0 0 0 0 1 0 0 0]
[0 1 0 0 0 0 0 0]
[0 1 0 0 0 0 0 0]
[0 0 0 0 0 1 0 0]
[0 0 0 0 0 0 0 1]
[0 0 0 0 0 0 0 1]
[0 0 0 0 0 0 0 0]]
0,13000,13001,13058,13098,13099,13120,99999
Initial start: Level 1
[0 0 1 1 0 0 1 0]
Level 2 start
[0 2 0 0 0 0 0 1]
Level 3 start
[0 0 0 0 2 0 0 0]
Level 4 start
[0 0 0 0 0 2 0 0]
Level 5 start
[0 0 0 0 0 0 0 2]