- Applications updating node execution map
- cbaNodeWalker - scripts cadence reverse engineering
- cbaWFMonitor
- cbaWFRepositoryConnector
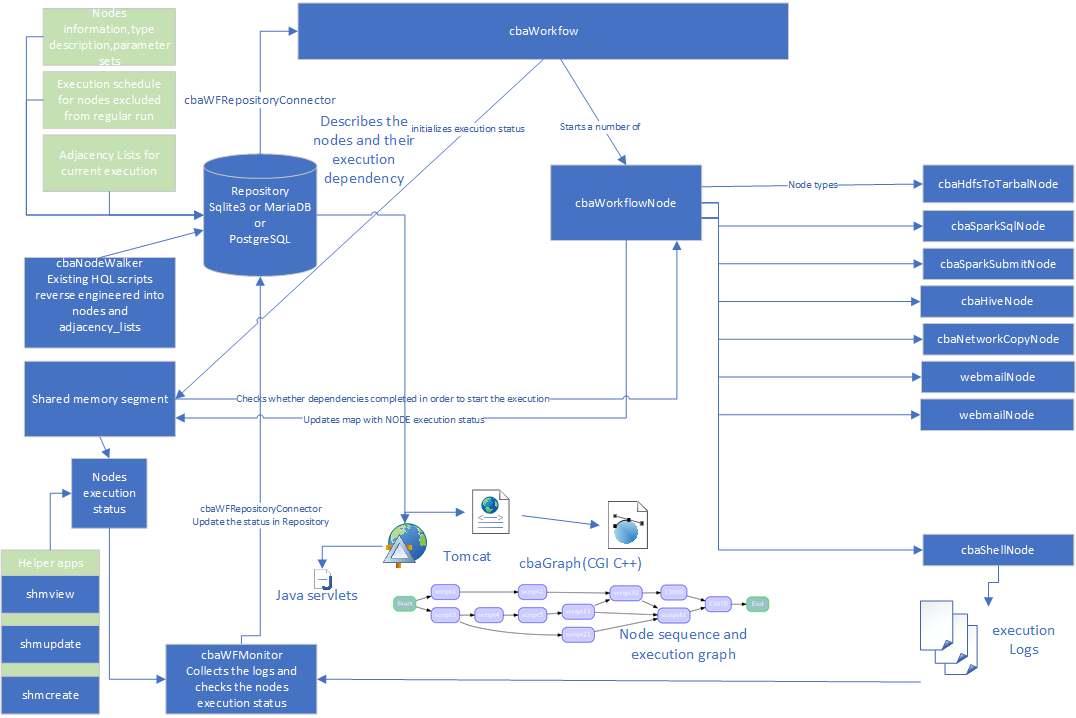
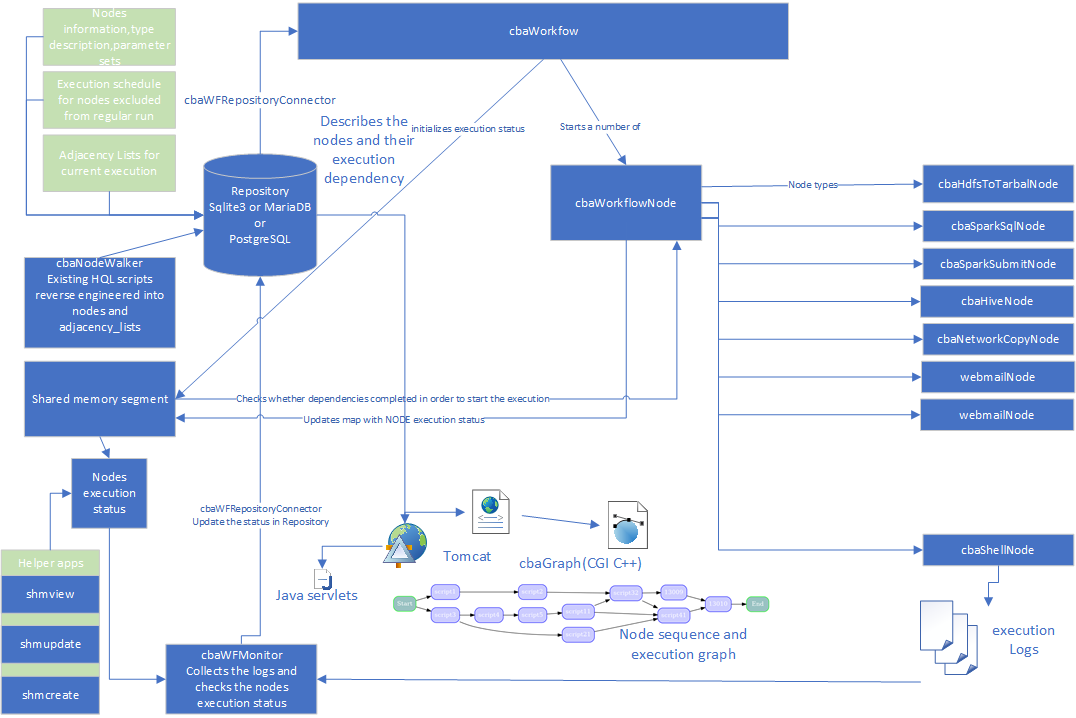
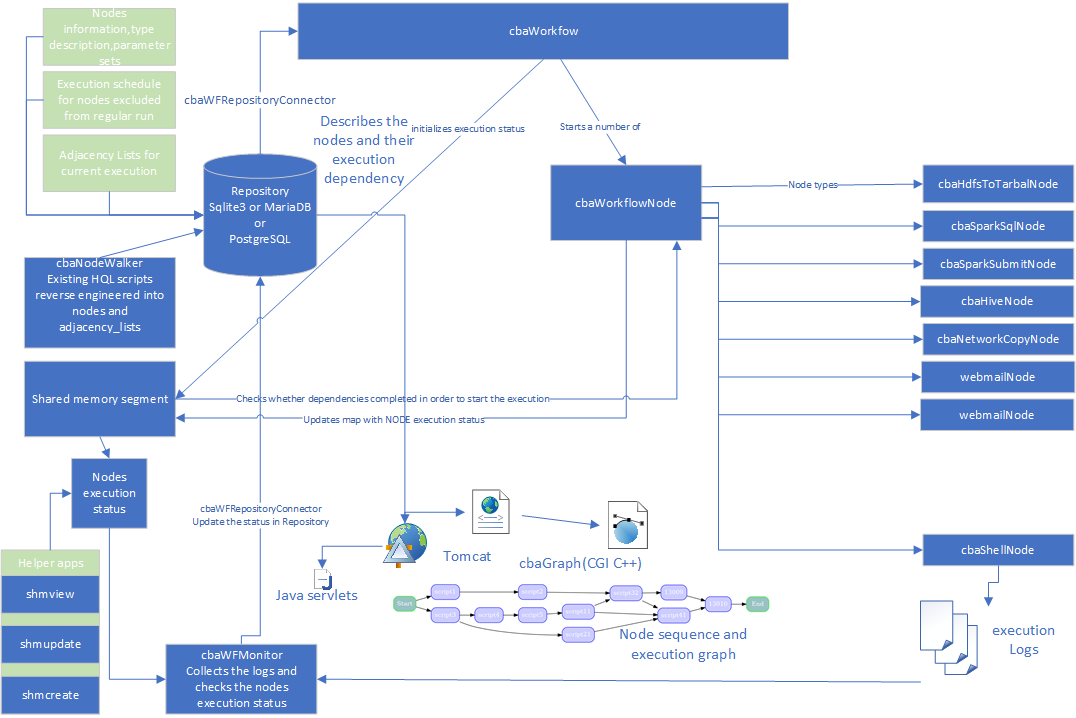
- cbaWorkflow implementation
- cbaWorkflowNode
- cbaWorkflow repository structure
- design and implementation for node levels start
- Shared memory segments
- Visual representation of the workflow using cbaGraph
General description
Workflow will obtain the description of the nodes from a repository (postgreSQL database) and will instantiate node objects.
Workflow will start a set of nodes which will execute themselves
workflow will obtain the dependencies of the current run from repository and pass the dependency to every node it creates.
the nodes will know what they depend on by storing a vector of node ids they depend on
the nodes will know how to execute themselves
the nodes will have a method which will run the execution when the dependencies have completed, or sleep if they have not
the nodes will update a map in shared memory with their progress
the nodes will check a shared memory map whether the nodes they depend on have completed execution
workflow will keep the list of the allocated node objects and delete them after their job is completed
workflow will rerun the node which failed execution
workflow will monitor the progress of the execution and asynchronously update the database with the information on start time, end time and progress
cbaWorkflow framework is implemented using C++. Compiled using gCC 5.04, std=C++17, boost headers and libraries version 1.72
its components rely on connectivity libraries for Repository connection.
Resources
Repository
Repository database - sqlite3, or MariaDB, or PostgreSQL
repository stores the following information:
nodes types information in table node_types
nodes , their type, execution parameters in the table nodes
hierarchical dependencies information about node dependencies in the table adjacency_lists (nodeFrom, nodeTo)
information about the current execution status in the table nodes_execution_status (node_id, execution_status)
information about the current execution timing in the table nodes_execution_stats(node_id,start_time,complete_time)
information about execution schedule in chrontab format for the nodes executed on specific days of week or month (node_id, scheduled_days)
cbaWFRepositoryConnector
is used to retrieve data from repository(RDBMS like PostgreSQL, Squilte3, MariaDB)
the application is linked with libcbaWFRepositoryConnector.so and loads dynamically cbaWFRepositoryConnector derived classes, which are implemented in the respective shared libraries.
Connectivity libraries have to be installed on the host:
C libpq.so library - to retrieve data from PostgreSQL
C libsqlite3.so - to retrieve data from sqlite3(possibly it could be incorporated into the Connector)
C libmariadb.so - to retrieve data from mariaDB
Tomcat application server
servlets functionality:
adding nodes and dependencies for the small to medium sized pipelines
present reports of execution timings
present execution graph and nodes states using graphviz librarires and cbaGraph class in libcbaGraph.so
libcbaGraph.so - calling the graphviz libraries to generate a graph of execution. The data for the nodes are retrieved from the nodes table in repository, the dependencies are retrieved from the adjacency_lists table in repository
Connectivity: JDBC drivers need to be installed for repository connection
Shared memory
boost_managed_memory, boost_interprocess - to keep the execution status in the shared memory and named semaphores to synchronize the access to shared memory
Helper applications
cbaNodeWalker - reverse engineering a set of hql/sql scripts to obtain information on the nodes(a script) and execution dependency(stored in adjacency_lists table in repository as nodeFrom→nodeTo format).
shmcreate - creates a shared memory segment from a file of adjacency_lists – used for testing purposes primarily
shmview - shows the nodes execution states in the map in shared memory -used for establishing the current execution status, as repository information is lagging
shmupdate - updates the node execution status - a use case: a node execution fails. The node task is executed outside of the framework (by running hql, dropping the table etc). To continue execution the node status needs to be set to 4(completed) or 3(skipped)
cbaWorkflowNode
workflow framework will call the applications written in different languages and get the result codes of execution and logs parsing.
the cbaWorkflowNode is the base class for all the node types and derived classes may be created in separate libraries and loaded dynamically by cbaWorkflow based on the node_types table descriptsion of node and shared object.
every cbaWorkflow node know how to execute itself.
the following nodes are available currently
cbaSparkSubmitNode: scala/java generated jars for spark-submit (possible, but not tested use is pyspark scripts)
cbaSparkSqlNode spark sql scripts for spark-sql executable(Spark 3)
cbaHiveNode - hql scripts executed in hive
cbaShellNode - any command executed using a shell interpreter, including hadoop ones
cbaHdfsNode - hdfs based commands
Neo4j use is being investigated to generate a dependency graph, which could be exported as Cypher query to get a complex list of dependencies.
{kind=link}
{kind=link}
{kind=link}
{kind=link}