overview
The repository is used for the following purposes:
- initial creation of nodes of the current run cbaWorkflow
- Storing the statistics of the execution from the logs by cbaWFMonitor
- Storing the status of the nodes execution by the cbaWFMonitor
The repository is used by the other applications, like Tomcat interface for visualizing the dependencies or execution, or Quality assurance tool which uses the completed status of the nodes for the starting the data profiling.
The repository is not used by the nodes to set or check their execution status, shared memory is used for that.
Currently cbaWorkflow supports repository creation in the following RDMBS:
- PostgreSQL
- MariaDB
- Sqlite3
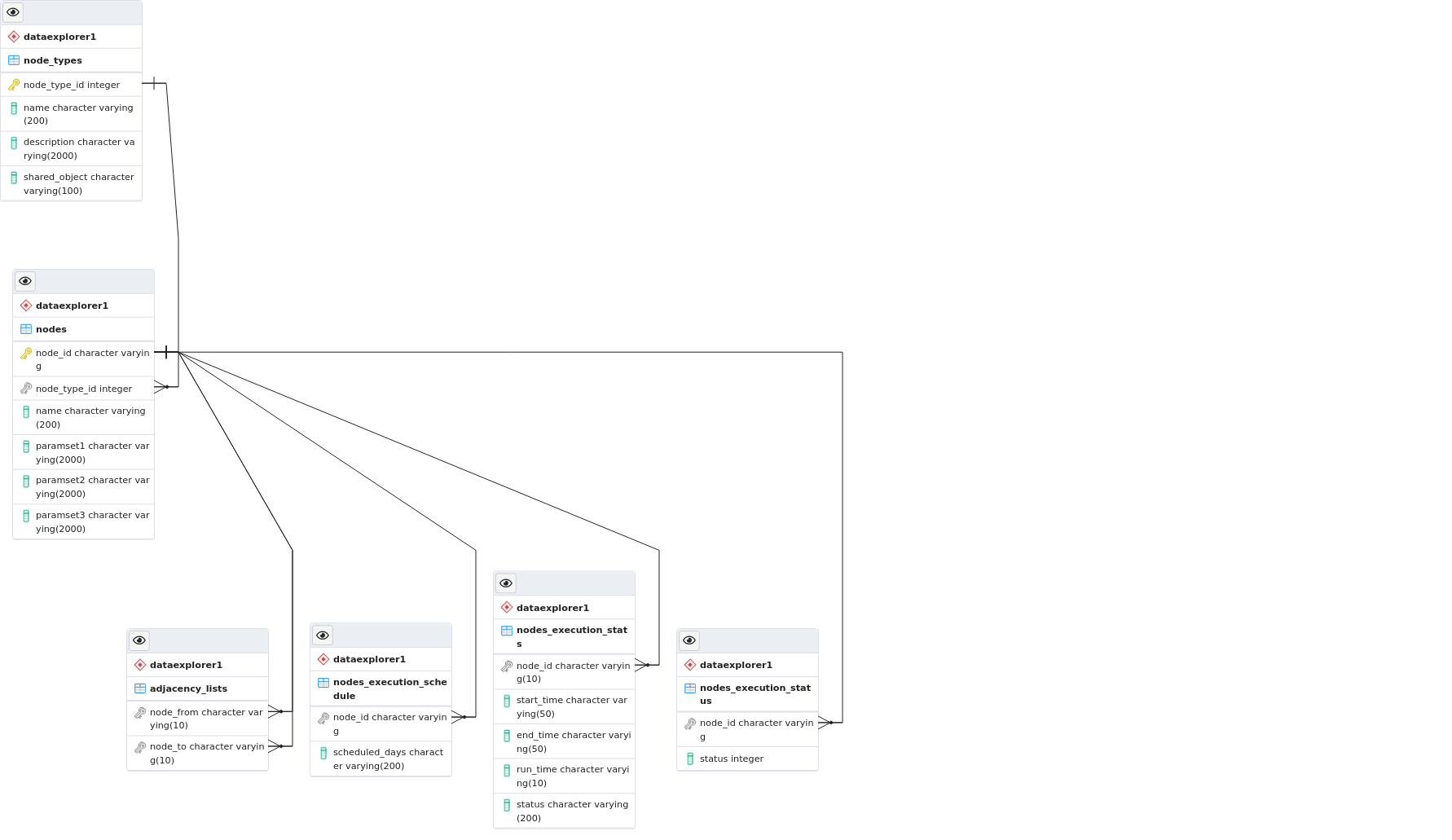
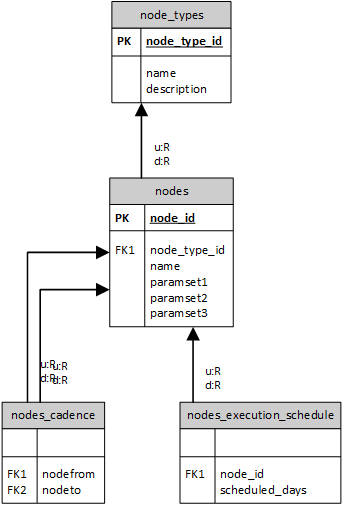
database diagram
Objective
the database repository describes an acyclic directional graph of cbaNodes execution path.
it is used for initial load of the application structures.
cbaWorkflow object is reading the repository and creates cbaNodes objects based on their description.
each cbaNode object will have a reverse adacency list of its parents.
cbaWorkflow starts the cbaNodes proactively based on the levels of execution
Levels of execution are calculated and determined by the adjacency lists obtained from the adjacency_lists table and stored in the application structures.
cbaWFMonitor collects the data about the nodes status from shared memory and stores it in the nodes_execution_status table
cbaWFMonitor collects the data from the execution logs of the nodes and stores it in the nodes_execution_stats table.
node_types
The table contains the types of nodes. each type is a cbaNode derived class.
information in the table is used to load dynamically the implementation of the derived class by the cbaWorkflow object
Structure:

node_type_id - a unique identifier of the node type
name - a name of the node type, e.g
"startWorkflowNode"
"sparkSQLNode"
"sparkSubmitNode"
"shellNode"
"networkCopyNode"
"hdfsExecNode"
"hdfsToTarbalNode"
"endWorkflowNode"
description - general description of the node functionality
shared_object - the name of the shared library to be loaded dynamically to create the node_type
"libcbaStartNode.so"
"libcbaSparkSQLNode.so"
"libcbaSparkSubmitNode.so"
"libcbaEndNode.so"
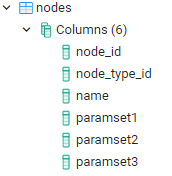
nodes
contains information about all the nodes, defined for the workflow.
node_type_id has to be defined in the node_types.
Structure:
adjacency_lists
The table contains the adjacency lists of the nodes.
Each record contains information about the cbaNodes edges as vertex (nodefrom) and vertex (nodeto)connected by an edge
The table is used by the cbaWorkflow to generate an adjacency matrix and establish the levels of execution.
the nodes have to be defined in the nodes table.
only the nodes in the adjacency_lists will be part of the current run.
Structure:
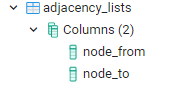
nodefrom - id of the vertex edge start node
nodeto - id of the edge end node.
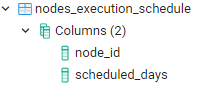
nodes_execution_schedule
the nodes in the table have special execution schedule and skipped from the regular execution.
node_id has to be defined in the nodes table
scheduled_days follows crontab pattern.
* * * * 0,5,6 -means the node_id will be executed on Sunday,Friday,Saturday and skipped on the other days
* * 6 3 * - means the node_id will be executed only on the 6th of March
Structure:
nodes_execution_status
during the execution nodes update their status in the shared memory map.
cbaWFMonitor picks up the values at the polling interval (60 seconds by default) and stores them in this table.
A graphviz based application is picking up the values from this table and generates a webpage served by Tomcat.
Structure:
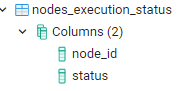
nodes_execution_stats
during the execution nodes generate logs with their start_time and status.
cbaWFMonitor picks up the values and puts them into this table.
The table is used by a Tomcat servlet to generate a statistics page.
Structure:
{kind=link}
{kind=link}
{kind=link}